컴퓨터 비전
컴퓨터 비전의 목표는 컴퓨터에게 생물이 이해하는 방식 혹은 그보다 더 나은 방식으로 이 픽셀을 이해하는 방법을 가르치는 것이다.
주요 작업 및 애플리케이션
콘텐츠 인식
컴퓨터 비전의 주요 목적은 이미지를 이해하는 것, 즉 픽셀로부터 유의미한, 의미론적 정보를 추출하는 것이다. 그 하위 영역을 정리할 수 있다.
객체 분류
객체 분류는 다음 그림에서 보듯이 사전 정의된 집합의 이미지에 적절한 레이블을 할당하는 작업
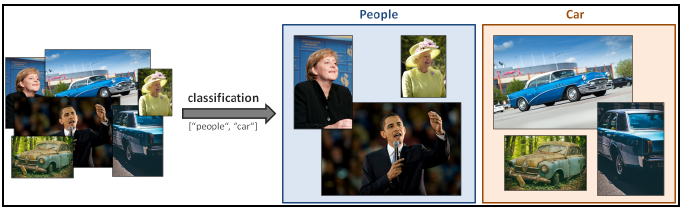
이 분야는 공통적으로 텍스트를 디지털화하는 것과 이미지 데이터베이스에 주석을 다는 작업에 적용할 수 있다.
객체 식별
클래스의 특정 인스턴스를 인식하는 법을 학습한다.
사람을 식별하는 얼굴 특징에 중점을 두고 다른 이미지들 사이에서 그 얼굴을 식별한다. 객체 식별은 데이터셋을 클러스터링하는 절차로 볼 수 있으며, 종종 데이터셋 분석 개념에 적용한다.

객체 탐지와 위치 측정
이미지 내의 특정 요소를 탐지하는 것을 들 수 있다.

객체 및 인스턴스 분할
분할은 단순히 인식된 요소의 경계 상자를 제공하는 것이 아니라 특정 클래스 혹은 특정 클래스의 인스턴스에 속한 모든 픽셀에 레이블을 단 마스크를 반환한다.

자세 추정
Pose estimation 은 어떤 작업을 목표를 하느냐에 따라 다양한 의미를 갖는다. 고정된 객체의 경우, 일반적으로 3차원 공간에서 카메라를 기준으로 객체의 위치와 방향을 추정하는 것을 뜻한다.
고정되지 않은 요소의 경우 하부 요소들의 상대적인 위치를 추정하는 것을 뜻한다. 일반적으로 사람의 자세를 인식하거나 수화를 이해하는 데 적용할 수 있다.

2D 이미지 표현에 기반해 3D 환경에서 카메라 기준으로 그 요소의 실제 위치와 방향을 평가하는 작업을 한다.
동영상 분석
컴퓨터 비전은 동영상에도 적용될 수 있다. 동영상 스트림을 프레임 단위로 분석해야 하는 경우 어떤 작업에서는 시간적 일관성을 고려하기 위해 이미지 시퀀스를 전체로 고려해야 한다.
인스턴스 추적
동영상 스트림의 일부 작업은 순수하게 각 프레임을 분리해 연구하면 되지만, 앞의 이미지에서 연역해서 새로운 프레임을 어떻게 처리할지 알려주거나 전체 이미지 시퀀스를 예측의 입력으로 취하는 것이 더 효율적이다. 추적
추적은 프레임마다 탐지와 식별 기법을 적용하믕로써 이뤄질 수 있다. 그렇지만 앞으로 올 프레임에서 인스턴스의 위치를 부분적으로 예측하기 위해 이전 결과를 ㅅ용해 인스턴스의 움직임을 모델링하는 것이 효율적이다. 따라서 여기서는 움직임의 연속성 Motion Continuity 이 핵심 속성이다.
행동 인식
반면 행동 인식은 이미지 시퀀스를 놓고 봐야만 하는 작업의 하나다.
행동 인식이란 사전 정의된 집합 중에서 특정 해동을 인식하는 것이다.

움직임 추정
움직이는 요소를 인식하려는 대신, 일부 기법은 동영상에서 포착된 실제 속도/궤도를 추정하는 데 집중한다. 이 또한 표시된 장면과 관련해 카메라 자체의 움직임을 평가하는 것이 일반적이다.
콘텐츠-인식 이미지본
이미지 자체를 개선하기 위해 적용할 수 있다.

장면 복원
하나 이상의 이미지가 주어졌을 때 장면의 3차원 기하학적 구졸르 복원하는 작업