가장 널리 알려진 CNN 구조
1998 년 얀 르쿤, 손글시 숫자 인식에 널리 사용
| 층 | 종류 | 특성 맵 | 크기 | 커널 크기 | 스트라이드 | 활성화 함수 |
| 출력 | 완전 연결 | - | 10 | - | - | RBF |
| F6 | 완전 연결 | - | 84 | - | - | tanh |
| C5 | 합성곱 | 120 | 1-1 | 5-5 | 1 | tanh |
| S4 | 평균 풀링 | 16 | 5-5 | 2-2 | 2 | tanh |
| C3 | 합성곱 | 16 | 10-10 | 5-5 | 1 | tanh |
| S2 | 평균 풀링 | 6 | 14-14 | 2-2 | 2 | tanh |
| C1 | 합성곱 | 6 | 28-28 | 5-5 | 1 | tanh |
| 입력 | 입력 | 1 | 32-32 | - | - | - |
- 28 * 28 입력에 제로 패딩되고 정규화된다.
- 출력층은 가중치 벡터를 행렬 곱하는 대신, 각 뉴런에서 입력 벡터와 가중치 벡터 사이의 유클리드 거리를 출력한다. 각 출력은 이미지가 얼마나 특정 숫자 클래스에 속하는지 측정한다.
논문
역전파 알고리즘으로 훈련된 다층 신경망은 기울기 기반 학습 기술의 성공적이 ㄴ예, 최소한의 전처리로 고차원 패턴을 분류할 수 있는 의사 결정 표면을 합성할 수 있다. 이 논문은 수기 문자 인식에 적용된 다양한 방법을 검토, 2D 모양의 가변성을 처리하도록 설계된 Convolutional Nerural Networks 는 다른 모든 기술을 능가하는 것으로 나타난다.
자동 기계 학습의 접근방법 중 가장 성공적인 접근법은 수치 또는 그레이디언트 기반 학습이라고 할 수 있다.
학습 기계는 함수

를 계산한다. Z^p 는 p 번째 입력 패턴이고 W 는 매개 변수의 집합을 나타낸다. 패턴 인식 설정에서 출력 Y^p 는 패턴 Z^p 의 인식된 클래스 레이블로 해석되거나 각 클래스와 관련된 점수 또는 확률로 해석 될 수 있다.
손실 함수

는 패턴 Z^p 에 대한 올바른 또는 우너하는 출력 및 시스템에서 생성된 출력 간의 불일치를 측정한다. 평균 손실 함수 E_train 은 레이블이 지정된 훈련 세트에 대한 오류 E^p 의 평균이다.
가장 간단한 설정에서 학습 문제는 E_train(W) 를 최소화하는 W 의 값을 찾는 것으로 끝난다.
실제로 훈련 세트에서 관심있어하는 것은 오류율이며 실제로 사용된다. 이 성능은 테스트 세트라고 하는 훈련 세트에서 분리된 샘플 세트의 정확도를 측정하여 추정된다.
테스트 세트와 훈련 세트의 오류율 사이의 간격이 대략 다음과 같이 훈련 샘플의 수에 따라 감소한다.
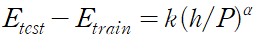

가장 간단한 경우, e(학습률) 은 상수이다. 더 복잡한 방법으로는 변수를 사용하거나 대각 행렬, 역행렬의 추정치로 대체한다.
헤시안 행렬, Conjugate Gradient method 를 사용할 수 있지만, 대규모 학습에 대한 이러한 방법은 매우 제한적이다.
널리 사용되는 방법은 online update 라고도 불리는 stochastic gradient algorithm 이다. 평균 기울기의 노이즈가 많거나 근사화된 버전을 사용하여 매개 변수 벡터를 업데이트하는 것으로 구성된다.

이 절차를 통해 매개 변수 벡터는 평균 궤적을 중심으로 변동하지만, 일반적으로 중복 샘플이 있는 대규모 훈련 세트에서 일반적인 경사 하강등의 방법보다 상당히 빠르게 수렴한다.
그레이디언트 기반 학습 절차는 1950 년대 후반부터 사용되었지만 대부분 선형 시스템으로 제한되었다. 복잡한 기계 학습 작업에 대한 간단한 경사 하강 기술의 놀라운 유용성은 3가지 사건에 의해 널리 인식되었다.
1. 손실 함수에 지역 최소치가 그리 큰 문제가 아니었다는 것
2. 여러 계층의 처리로 구성된 비선형 시스템에서 기울기를 계산하기 위해 간단하고 효율적인 절차인 역전파 알고리즘을 대중화한 것
3. 시그모이드 단위를 가진 다층 신경망에 적용된 역전파 절차가 복잡한 학습 과제를 해결할 수 있다는 것
local minima 이 다층 신경망에 문제가 되지 않는 것 같다는 사실은 이론적으로 미스터리다. 네트워크가 작업에 대해 크기가 초과되면 매개 변수 공간에 추가 차우너이 존재하면 도달할 수 없는 영역의 위험이 감소하는 것으로 추측된다.
필기 인식에서 가장 어려운 문제 중 하나는 개별 문자를 인식하는 것 뿐만 아니라 단어나 문장 내에서 이웃 문자를 구분하는 것인데, 이를 분할(segmentation) 이라고 한다. 표준이 된 이 작업을 수행하는 기술을 Heuristic OverSegmentation 이라고 한다.
휴리스틱 이미지 처리 기술을 사용하여 문자 간에 많은 수의 잠재적인 분할과 각 후보 캐릭터에 부여한 점수를 기반으로 분할의 최적 조합을 선택하는 것으로 구성된다.
이러한 모델에서 시스템의 정확도는 휴리스텍 의해 생성된 분할의 품질과 문자 조작, 여러 문자 또는 잘못 분할된 문자에서 올바르게 분할된 문자를 구별하는 인식기의 능력에 따라 달라진다.
이 작업을 수행하도록 인식기를 교육하는 것은 잘못 분할된 문자로 레이블이 지정된 데이터 베이스를 만드는 것이 어렵기 때문에 큰 과제가 된다. 가장 간단한 해결책은 이 분할기를 통해 문자열 이미지를 실행한 다음 모든 문자에 수동으로 레이블을 지정하는 것, 이는 비용이 많이 들 뿐만 아니라, 라벨링을 지속적으로 수행하는 것도 어렵다. 예를 들어 8의 오른쪽 절반은 3으로 표시?
첫 번째 솔루션은 문자 수준이 아닌, 문자의 전체 문자열 수준에서 시스템을 훈련하는 것이다. 그레이디언트 기반 학습의 개념은 이러한 목적으로 사용될 수 있다. 시스템은 오답 확률을 측정하는 전체 손실 함수를 최소화하도록 훈련되었다.
대부분의 실용적인 패턴 인식 시스템은 다수의 모듈로 구성된다.
Globally Trainable Systems
대부분의 실용적인 패턴 인식 시스템은 다수의 모듈로 구성된다. 대부분의 경우 모듈에서 모듈로 전달되는 정보는 호에 숫자 정보가 첨부된 그래프로 가장 잘 표현된다.
문서 수준에서 문자 오분류 가능성과 같은 글로벌 오류 측정을 최소화하도록 전체 시스템을 어떻게든 훈련시키는 것, 이상적으로 우리는 시스템의 모든 매개 변수와 관련하여 이 전역 손실 함수의 양호한 최소값을 찾고자 한다. 성능을 측정하는 손실 함수 E 를 시스템의 조정 가능한 매개변수 W 와 관련하여 미분 간으하게 할 수 있다면 우리는 그레이디언트 기반 학습을 사용하여 E 의 로컬 최소치를 찾을 수 있다.
하지만 시스템의 크기와 복잡성이 이를 다루기 어렵게 만들 것으로 보인다.
전역 손실 함수 E^p 가 미분가능하도록 전체 시스템은 미분 가능한 모듈의 feed forward network 구조로 구축된다. 각 모듈에 의해 구현되는 기능은 모듈의 내부 매개 변수 및 모듈의 입력과 관련하여 거의 모든 곳에서 연속적이고 미분가능해야 한다. 이 경우 잘 알려진 역전파 절차의 간단한 일반화를 사용하여 시스템 모든 매개 변수에 대한 손실 함수의 기울기를 효율적으로 계산할 수 있다.

벡터 함수의 야코비안ㅇ느 모든 입력에 대한 모든 출력의 부분 도함수를 포함하는 행렬이다.
첫 번째 방정식은 E^p(W) 의 기울기에 대한 일부 항을 계산하는 반면, 두 번째 방정식은 신경망에 대한 잘 알려진 역전파 절차에서와 같이 역방향 반복을 생성한다.
우리는 훈련 패턴에 걸쳐 그레이디언트를 편균하여 전체 그레이디언트를 얻을 수 있다. 많은 경우 야코비안 행렬을 명시적으로 계산할 필요가 없다는 점에 주목하는 것은 흥미롭다.
위 공식은 부분 도함수의 벡터가 있는 야코비안의 곱을 사용하며, 종종 야코비안을 미리 계산하지 않고 이 곱을 직접 계산하는 것이 더 쉽다. 일반적인 다층 신경망과 유사하게, 마지막 모듈을 제외한 모든 모듈은 외부에서 출력을 관찰할 수 없기 때문에 hidden_layer 라고 불린다.
대규모 예제 모음에서 복잡한 고차원 비선형 매핑을 학습할 수 있는 경사 하강법으로 훈련된 다층 네트워크의 능력은 이미지 인식 작업의 확실한 후보가 된다. 패턴 인식의 전통적인 모델에서 손으로 설계된 특징 추출기는 입력에서 관련 정보를 수집하고 관련 없는 변동성을 제거한다. 그런 다음 훈련 가능한 분류기는 결과 특성 벡터를 클래스로 분류한다.
일반적인 이미지는 수백 개의 변수(픽셀)가 있는 큰 이미지, 첫 번재 레이어에 100개의 은닉 노드가 있는fully-connected 신경망은 수만 개의 가중치가 포함되어 있다. 이렇게 많은 매개 변수는 시스템의 용량을 증가시킨다.
그러나 이미지 또는 음성에 대한 비정형 데이터의 주요 단점은 입력의 로컬 왜곡과 관련하여 내재된 불변성이 없다느 ㄴ것이다.
신경망의 고정 크기 입력 계층으로 전송되기 전에 문자 이미지 또는 기타 신호는 대략저긍로 크기를 정규화하고 입력 필드에 중심을 두어야 한다. 이러한 사전 처리는 완벽할 수 없다.
필기는 종종 단어 수준에서 정규화되어 개별 문자의 크기, 기울기 및 위치 차이르 ㄹ유발할 수 있다. 이는 쓰기 스타일의 가변성과 함께 입력 객체에서 고유한 특성의 위치에 변화를 초래한다.
원칙적으로, 충분한 크기의 완전히 연결된 네트워크는 그러한 변형과 관련하여 불변하는 출력을 생성하는 방법을 배울 수 있다. 이러한 작업을 학습하면 다양한 위치에 유사한 가중치 패턴을 가진 여러 단위가 배치되어 입력에 나타나는 모든 곳에서 구별되는 특징을 감지할 수 있다.
이러한 가중치 구성을 학습하려면 가능한 변형의 공간을 커버하기 위해 많은 수의 인스턴스가 필요하다.
CNN 에서 이동 불변성은 공간 전체에 걸쳐 가중치 컨볼루션의 복제를 강제함으로써 자동으로 얻어진다.
완전히 연결된 아키텍처의 단점은 입력의 토폴로지가 완전시 무시된다는 것이다. 입력 변수는 결과에 영향을 주지 않고 모든 순서로 표시될 수 있다. 반대로 이미지는 강력한 2D 로컬 구조를 가지고 있다. 공간적, 시간적으로 가까운 변수는 높은 상관관계가 있다.
지역 상관 관계는 공간적 또는 시간적 객체를 인식하기 전에 지역적 특징을 추출하고 결합하는 장점의 이유, 이웃 변수의 구성은 소수의 범주(모서리) 로 분류될 수 있기 때문,
CNN 은 수신 필드를 로컬로 제한하여 로컬 기능의 추출을 강제한다.
CNN 은 세 가지 아키텍처 아이디어를 결합하여 이동, 규모 및 왜곡 불변성을 보장한다. 즉, 로컬 수신 필드, 공유 가중치(가중치 복제) 및 공간 또는 시간적 하위 샘플링이다.

입력 평면은 대략적으로 크기가 정규화되고 중심에 있는 문자의 이미지를 수신한다. 계층의 각 단위는 이전 계층의 작은 이웃에 위치한 단위 집합으로부터 입력을 받는다.
LeNet-55 는 입력을 계산하지 않고 7개의 레이어로 구성되며 모두 훈련 가능한 변수를 포함한다. 입력은 32*32 픽셀 임지ㅣ이다. 이 값은 데이터 베이스에서 가장 큰 문자보다 훨씬 크다. 그 이유는 모서리와 같은 잠재적인 구별 특징이 가장 높은 수준의 특징 검출기의 수신 필드 중앙에 나타날 수 있기 때문이다.
입력 픽셀의 값은 배경(흰색)이 -0.1 값에 해당하고 검은색이 1.175 에 해당하도록 정규화한다. 이것은 평균 입력을 대략 0으로 만들고 분산을 1에 가깝게하여 학습을 가속화한다.
C1 은 6개의 특성 맵이 있는 CNN 이다. 각 특성 맵의 각 단위는 5*5 에 연결된다. 특성 맵의 크기는 28*28 이다. 156 개의 훈련 가능한 매개 변수와 122,304 개의 연결이 포함되어 있다. (6*6 *6),(28*28*6*6*6)
S2 는 14 * 14 인 6개의 특성 맵이 있는 하위 샘플링 레이어, C1과 2*2 와 연결, 12 개의 훈련 가능한 매개변수와 5880 개의 연결이 있다.
C3 은 16 개의 특성 맵이 있는 convolutional layer, 각 특성 맵의 단위는 5*5 와 연결, 아래 표는 각 C3 특성 맵에 의해 결합된 S2 특성 맵 세트를 보여준다.

왜 모든 S2 특성 맵을 C3 특성 맵에 연결하지 않는 이유는 두가지이다.
완전하지 않은 연결 방식은 연결 수를 합리적인 범위 내로 유지한다.
더 중요한 것은 이것이 네트워크의 대칭성을 깨도록 강요하기 때문이다. 서로 다른 특성 맵은 서로 다른 입력 집합을 얻기 때문에 서로 다른 특성을 추출해야 한다.
나머지 6개의 C3 특성 맵은 S2 에 있는 3 개의 특성 맵의 모든 연속 하위 집합에서 입력을 가져온다. 다음 6개는 4개의 연속된 모든 부분 집합에서 입력을 받는다. 다음 세 개는 네 개의 불연속 부분 집합에서 입력을 가져온다. 마지막 하나는 모든S2 특성 맵에서 입력을 가져온다.
C3 에는 1516 개의 훈련 가능한 매개변수와 151600 개의 연결이 있다.
S4 는 크기가 5*5 인 16 개의 특성 맵이 있는 하위 샘플링 레이어다. 32 개의 훈련 가능한 매개변수와 2000 개의 연결이 있다.
C5 는 120 개의 특성 맵이 있는 컨볼루션 레이어다. 각 유닛은 16 개의 특성 맵의 5*5 와 연결된다. S4 의 크기도 5*5 이므로 특성맵의 크기는 1*1 이다. 이는 S4 와 C5 간의 전체 연결에 해당한다. 48120 개의 훈련 가능한 연결이 있다.
F6 은 84 개의 유닛이 포함, C5 d에 오나전히 연결되어 있다. 10164 개의 훈련 가능한 매개변수를 가지고 있다.
마지막으로 출력 레이어는 각각 84 개의 입력이 있는 각 클래스에 하나씩 잇는 유클리드 방사 기저 함수 단위 RBF 로 구성된다.
각 출력 RBF 장치는 입력 벡터와 매개 변수 벡터 사이의 유클리드 거리를 계산한다. 파라미터 벡터로부터 입력이 멀어질수록 RBF 출력은 커진다.
위 네트워크에서 사용할 수 있는 가장 간단한 출력 손실 함수는 최대우도 추정 기준이며, 이 경우 최소 제곱 오차와 같다.
'implement_neural_network_structure' 카테고리의 다른 글
| Xception (0) | 2023.04.07 |
|---|---|
| ResNet (0) | 2023.04.07 |
| GoogLeNet (0) | 2023.04.06 |
| AlexNet (0) | 2023.04.06 |

