서포트 벡터 머신 Support vector mechine, SVM은 매우 강력하고 선형이나 비선형 분류, 회귀, 이상치 탐색에도 사용할 수 있는 다목적 머신러닝 모델
5.1 선형 SVM 분류
결정 경계가 샘플에 너무 가까울 경우 새로운 샘플에 대해서는 잘 작동하지 못한다. SVM의 경우 훈련 샘플로부터 결정 경계가 가능한 한 멀리 떨어져 있다. 클래스 사이에 폭이 넓은 도로를 찾는 것으로 생각할 수 있다. 라지 마진 분류 Large Margin Classification 라고 한다. 도로 바깥쪽에 훈련 샘플을 더 추가해도 결정 경계에는 전혀 영향을 미치지 않는다. 도로 경계에 위치한 샘플에 의해 전적으로 결정된다.
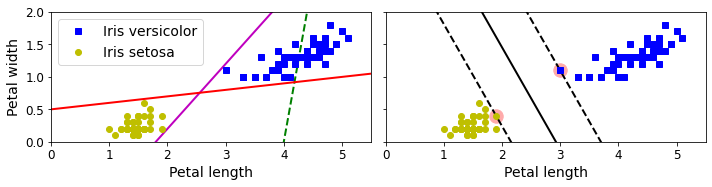
이런 샘플을 서포트 벡터 Support vector 라고 한다.
SVM은 특성의 스케일에 민감하다. 특성의 스케일을 조정하면 결정 경계가 좋아진다.

5.1.1 소프트 마진 분류
모든 샘플이 도로 바깥쪽에 올바르게 분류되어 있다면 하드 마진 분류 Hard Margin Classification라고 한다. 하드 마진 분류기의 문제점으로
- 데이터가 선형적으로 구분될 수 있어야 제대로 작동
- 이상치에 민감하다.

두가지가 있다. 하드 마진을 찾을 수 없거나 결정 경계가 매우 작을 수 있다.
이런 문제를 피하려면 좀 더 유연한 모델이 필요하다. 도로의 폭을 가능한 한 넓게 유지하는 것과 마진 오류 margin violation(샘플이 도로 중간이나 반대쪽에 있는 경우) 사이에 적절한 균형을 잡아야 한다.
이를 소프트 마진 분류 Soft margin classification 라고 한다.
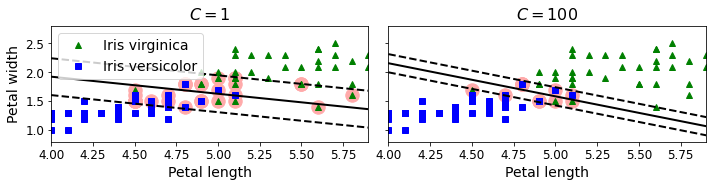
사이킷런의 SVM 모델을 만들 때 C는 낮게 설정하면 높은 일반화 성능을 가진다.
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris["data"][:,(2, 3)] # 꽃잎 길이, 넓이
y = (iris["target"] == 2).astype(np.float64)
svm_clf = (Pipeline([
("scaler",StandardScaler()),
("linear_svc", LinearSVC(C=1, loss="hinge")),
]))
svm_clf.fit(X, y)
svm_clf.predict([[5.5, 1.7]])
>>>
array([1.])Iris-virginia 품종을 감지하기 위해 선형 SVM 모델을 훈련시킨다. C=1 과 힌지 손실 hinge loss 함수를 적용한 LinearSVC 클래스를 사용한다
선형 SVM 분류기를 훈련시키기 위해 일반적인 확률적 경사 하강법을 적용한다. LinearSVC 만큼 빠르게 수렴하진 않지만 데이터셋이 아주 커서 메모리에 적재할 수 없거나 온라인 학습으로 분류 문제를 다룰 때는 유용하다.
LinearSVC는 규제에 편향을 포함시킨다. 그래서 훈련 세트에서 평균을 빼서 중앙에 맞춰야 한다. StandardScaler를 사용하여 데이터 스케일을 맞추면 자동으로 된다. loss 매개변수를 hinge로 지정, 훈련 샘플보다 특성이 많지 않다면 성능을 높이기 위해 dual 매개변수를 False로 지정한다.
5.2 비선형 SVM 분류
선형 SVM 분류기가 효율적이고 많은 경우 잘 작동하지만, 선형적으로 분류할 수 없는 데이터셋이 많음, 비선형 데이터셋을 다루는 한 가지 방법은 다항 특성과 같은 특성을 더 추가하는 것 이렇게 하면 선형적으로 구분되는 데이터셋이 만들어질 수 있다.

사이킷런에서 이를 구현하기 위해 PolynomialFeatrues 변환기와 StandardScaler, LinearSVC 를 연결하여 Pipeline을 만든다.
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
X, y = make_moons(n_samples=100, noise=0.15)
polynoma_svm_clf = Pipeline([
("poly_feature", PolynomialFeatures(degree=3)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge"))
])
polynoma_svm_clf.fit(X, y)
5.2.1 다항식 커널
다항식 특성을 추가하는 것은 간단하고 모든 머신러닝 알고리즘에서 잘 작동한다. 하지만 낮은 차수의 다항식은 매우 복잡한 데이터셋을 잘 표현하지 못하고 높은 차수의 다항식은 많은 특성을 추가하므로 모델을 느리게 만든다.
다행히도 SVM을 사용할 땐 커널 트릭 kernel trick을 적용해 실제로 특성을 추가하지 않으면서 다항식 특성을 추가한 것과 같은 결과를 얻을 수 있다.
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
])
poly_kernel_svm_clf.fit(X, y)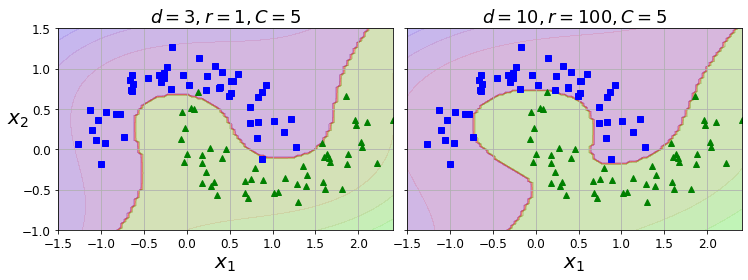
이 코드는 3차 다항식 커널을 사용해 SVM 분류기를 훈련, 오른쪽 그래프는 10차 다항식 커널을 사용한 또 다른 SVM 분류기이다. 매개변수 coef0가 모델이 높은 차수와 낮은 차수에 얼마나 영향을 받을지 조절한다.
coef0 매개변수는 상수항 r이다. 다항식 커널은 차수가 높아질수록 1보다 작은 값과 1보다 큰 값의 차이가 크게 벌어지므로 coef0 을 적절한 값으로 지정하면 고차항의 영향을 줄일 수 있다.기본값은 0이다.
5.2.2 유사도 특성
비선형 특성을 다루는 또 다른 기법은 각 샘플이 특정 랜드마크 Landmark 와 얼마나 닮았는지 측정하는 유사도 함수 similarlity function 로 계산한 특성을 추가하는 것이다. 예를 들어 앞에서 본 1차원 데이터셋에 두 개의 갠드마크 x1=-2와 x1 = 1 을 추가한다. 그리고 r = 0.3 인 가우시안 방사 기저 함수 radial basis function (RBF) 를 유사도 함수로 정의한다.
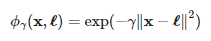
이 함수의 값은 0 (랜드마크에서 아주 멀리 떨어진 경우) 부터 1(랜드마크와 같은 위치일 경우)까지 변화하며 종 모양으로 나타난다. 위 식의 l이 랜드마크 지점이다. r는 0보다 커야 하며 값이 작을수록 폭이 넓은 좋 모양이 된다.
이제 새로운 특성을 만들 준비가 되었다. 예를 들어 x1 = -1 샘플을 살펴본다. 이 샘플은 첫 번째 랜드마크에서 1만큼 떨어져 있고 두 번째 랜드마크에서 2만큼 떨어져 있다. 그러므로 새로만든 특성은 exp(-0.3*1^2) = 0.74, exp(-0.3*2^2) = 0.30 이다.

오른쪽 그래프는 변환된 데이터 셋을 보여준다. 원본 특성은 뺏는다. 이제 선형적으로 구분이 가능해진다.
랜드마크를 선택하는 간단한 방법은 모든 샘플 위치에 랜드마크를 설정하는 것이다. 이렇게 하면 차원이 매우 커지고 따라서 변환된 훈련 세트가 선형적으로 구분될 가능성이 높다.
훈련 세트에 있는 n개의 특성을 가진 m개의 샘플이 m개의 특성을 가진 m개의 샘플로 변환된다는 것이다.
5.2.3 가우시안 RBF 커널
다항 특성 방식과 마찬가지로 유사도 특성 방식도 머신러닝 알고리즘에 유용하게 사용될 수 있다. 추가 특성을 모두 계산하려면 연산 비용이 많이 걸린다. 여기서 커널 트릭이 한 번 더 SVM의 마법을 만든다. 유사도 특성을 많이 추가하는 것과 같은 비슷한 결과를 얻을 수 있다.
가우시안 RBF 커널을 사용한 SVC 모델을 시도
rbf_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))
])
rbf_kernel_svm_clf.fit(X,y)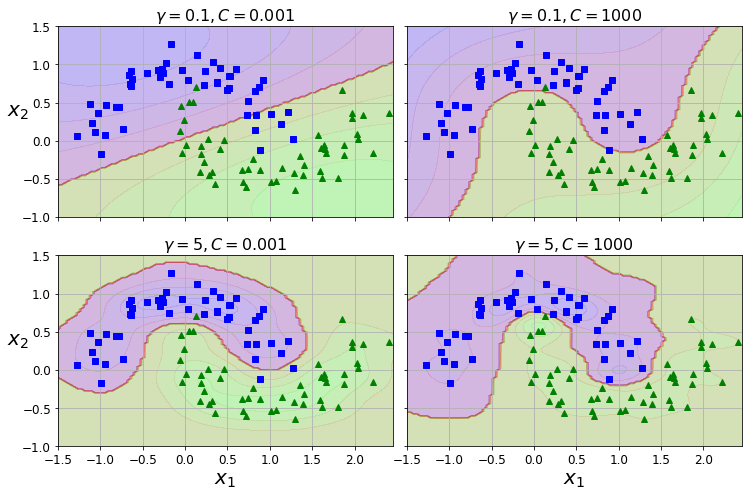
gamma 를 증가시키면 종 모양 그래프가 좁아져서 각 샘플의 영향 범위가 작아진다. 결정 경계가 조금 더 불규칙해지고 각 샘플을 따라 구불구불하게 휘어진다. 반대로 작은 gamma 값은 넓은 종 모양 그래프를 만들며 샘플이 넓은 범위에 걸쳐 영향을 주므로 결정 경계가 더 부드러워진다.
결국 하이퍼파라미터 r이 규제의 역할을 한다. 과대적합일 경우 감소, 과소적합일 경우 증가
5.2.4 계산 복잡도
LinearSVC 파이썬 클래스는 선형 SVM을 위한 최적화된 알고리즘을 구현한 liblinear 라이브러리를 기반으로 한다. 이는 훈련 샘플과 특성 수에 선형적으로 늘어난다. 정밀도를 높이면 수행 시간이 길어진다. 이는 허용오차 하이퍼파라미터로 조절한다.
SVC는 커널 트릭 알고리즘을 구현한 libsvm 라이브러리를 기반으로 시간 복잡도가 m^2, m^3으로 훈련 샘플 수가 커지면 엄청나게 느려진다. 복잡하지만 작은 훈련 세트에 이 알고리즘이 잘 맞는다. 특히 희소 특성 sparse features 인 경우에는 잘 확장된다. 이런 경우 알고리즘의 성능이 샘플이 가진 0이 아닌 특성의 평균 수에 비례한다.
5.3 SVM 회귀
SVM 알고리즘은 다목적으로 사용할 수 있다. SVM 을 분류가 아니라 회귀에 적용하는 방법은 목표를 반대로 하는 것이다. 일정한 마진 오류 안에서 두 클래스 간의 도로 폭이 가능한 한 최대가 되도록 하는 대신, SVM 회귀는 제한된 마진 오류 안에서 도로 안에 가능한 한 많은 샘플이 들어가도록 학습한다. 도로의 폭은 하이퍼파라미터 e로 조절한다.

그림은 무작위로 생성한 선형 데이터셋에 훈련시킨 두 개의 선형 SVM 회귀 모델을 보여준다. 하나는 마진을 크게, 다른 하나는 마진을 작게 설정했다.
마진 안에서는 훈련 샘플이 추가되어도 모델의 예측에는 영향이 없다. 그래서 이 모델을 e에 민감하지 않다고 말한다.
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon=1.5, random_state=42)
svm_reg.fit(X, y)사이킷런의 LinearSVR 을 사용해 선형 SVM 회귀를 적용해본다. 위 코드는 왼쪽 그래프에 해당하는 모델을 만든다.
비선형 회귀 작업을 처리하려면 커널 SVM 모델을 사용한다.
from sklearn.svm import SVR
svm_poly_reg1 = SVR(kernel="poly", degree=2, C=100, epsilon=0.1, gamma="scale")
svm_poly_reg2 = SVR(kernel="poly", degree=2, C=0.01, epsilon=0.1, gamma="scale")
svm_poly_reg1.fit(X, y)
svm_poly_reg2.fit(X, y)
위 코드는 사이킷런의 SVR을 사용해 위 그래프에 해당하는 모델을 만든다. SVR은 SVC의 회귀 버전이다.
SVM을 이상치 탐지에도 사용할 수 있다. https://goo.gl/cqU71e
2.7. Novelty and Outlier Detection
Many applications require being able to decide whether a new observation belongs to the same distribution as existing observations (it is an inlier), or should be considered as different (it is an ...
scikit-learn.org
5.4 SVM 이론
SVM의 알고리즘에 대해 알아본다.
5.4.1 결정 함수와 예측
선형 SVM 분류기 모델은 단순히 결정 함수 w^Tx + b 를 계산해서 새로운 샘플 x의 클래스를 예측한다.
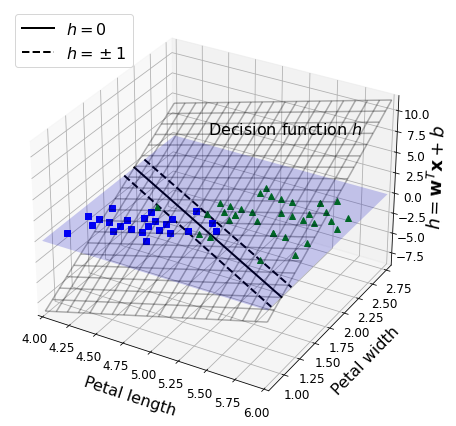
특성이 두 개인 더이터셋의 결정 함수를 보여준다. 결정 경계는 결정 함수의 값이 0인 점들로 이루어져 있다. 이는 두 평면의 교차점으로 직선이다.
점선은 결정 함수의 값이 1또는 -1인 점들을 나타낸다. 이 선분은 결정 경계에 나란하고 일정한 거리만큼 떨어져서 마진을 형성하고 있다.
선형 SVM 분류기를 훈련한다는 것은 마진 오류를 하나도 발생하지 않거나 제한적인 마진 오류를 가지면서 가능한 한 마진을 크게 하는 w와 b를 찾는 것이다.
5.4.2 목적 함수
결정 함수의 기울기를 생각해보면 이는 가중치 벡터의 노름 ||w||와 같다. 이 기울기를 2로 나누면 결정 함수의 값이 +-1이 되는 점들이 결정 경계로부터 2배만큼 더 멀어진다. 즉 기울기를 2로 나누는 것은 마진에 2를 곱하는 것과 같다.
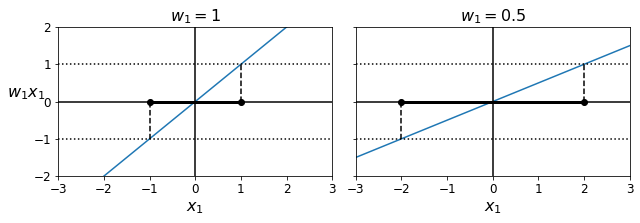
가중치 벡터 w가 작아질수록 마진은 커진다.
마진을 크게 하기 위해 ||w||를 최소화하려고 한다. 마진 오류를 하나도 만들지 않으려면, 결정 함수가 모든 양성 훈련 샘플에서는 1보다 커야 하고 음성 샘플에서는 -1보다 작아야 한다.
그러므로 하드 마진 선형 SVM 분류기의 목적 함수를 최적화 constrained optimization 문제로 표현할 수 있다.


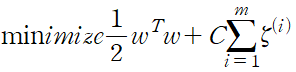

5.4.3 콰드라틱 프로그래밍
하드 마진과 소프트 마진 문제는 모두 선형적인 제약 조건이 있는 볼록 함수의 이차 최적화 문제이다. 이런 문제를 콰드라틱 프로그래밍 quadratic programming(QP) 문제라고 한다.
~
5.4.4 쌍대 문제
5.4.5 커널 SVM
2차원 데이터셋에 2차 다항식 변환을 적용하고 선형 SVM 분류기를 변환된 이 훈련 세트에 적용한다고 하자. 아래 식은 우리가 적용하고자 하는 2차 다항식 매핑 함수 Ø이다.


Ø가 위 식에 정의된 2차 다항식 변환이라면 변환된 벡터의 점곱을 간단하게 바꿀 수 있다.
그래서 실제로 훈련 샘플을 변환할 필요가 없다. 즉, 점급을 제곱으로 바꾸기만 하면된다. 결괏값은 실제로 훈련 샘플을 어렵게 변환해서 SVM 알고리즘을 적용하는 것과 완전히 같고, 계산량 측면에서 효율적이다. 이것이 커널 트릭이다.
함수 K(a,b) = (a^T b)^2 을 2차 다항식 커널이라고 부른다. 머신러닝에서 커널은 변환 Ø을 계산하지 않고 원래 벡터 a와 b에 기반하여 점곱을 계산할 수 있는 함수이다.아직 매듭짓지 못한 부분이 있다. ~~5.4.6 온라인 SVM
온라인 SVM 분류기에 대해 알아본다.
온라인 SVM을 분류기를 구현하는 한 가지 방법은 원 문제로부터 유도된 비용 함수를 최소화하기 위한 경사 하강법을 사용하는 것이다.
~~
'책 > Hands-On Machine Learning' 카테고리의 다른 글
| 7. 앙상블 학습과 랜덤 포레스트 (1) | 2022.10.07 |
|---|---|
| 6. 결정 트리 (0) | 2022.10.07 |
| 4. 모델 훈련 (0) | 2022.10.07 |
| 3. 분류 (1) | 2022.10.07 |
| 2. 머신러닝 프로젝트 처음부터 끝까지 (0) | 2022.10.06 |



