1.1 머신러닝이란?
머신러닝은 데이터에서부터 학습하도록 컴퓨터를 프로그래밍하는 과학이다.
- 머신러닝은 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구 분야 - 아서 새뮤얼, 1959
- 작업 T에 대한 성능 P를 측정, 경험 E로 인한 성능 향상 시 T와 P에 대해 E로 학습한 것 - 톰 미첼, 1997
일반적인 정의와 공학적인 정의
스팸 필터는 스팸 메일과 일반 메일의 샘플을 이용해 스팸 메일 구분법을 배울 수 있는 머신러닝 프로그램이다. 시스템이 학습하는 데 사용하는 샘플을 훈련 세트 training set라고 하고 각 훈련 데이터를 훈련 사례 training instance(혹은 샘플)라고 한다. 이 경우 작업 T는 새로운 메일이 스팸인지를 구분하는 것이고, 경험 E는 훈련 데이터 training data이며, 성능 측정 P는 직접 정의해야 한다. 예를 들면 정확히 분류된 메일의 비율을 P로 사용할 수 있다. 이 성능 측정을 정확도 accuracy라고 부르며 분류 작업에 자주 사용된다.
1.2 왜 머신러닝을 사용하는가?
전통적인 프로그래밍 기법을 사용한다면 문제가 어렵기 때문에 규칙이 점점 길고 복잡해지므로 유지 보수하기 매우 힘들어진다.
반면 머신러닝 기법에 기반을 둔 스팸 필터는 일반 메일에 비해 스팸에 자주 나타나는 패턴을 감지하여 어떤 단어와 구절이 스팸 메일을 판단하는 데 좋은 기준인지 자동으로 학습한다.
머신러닝이 유용한 또 다른 분야는 전통적인 방식으로는 너무 복잡하거나 알려진 알고리즘이 없는 경우이다. 음성 인식 speech recognition을 예로 들 수 있다.
우리는 머신러닝을 통해 배울 수도 있다. 즉, 머신러닝 알고리즘이 학습한 것을 조사할 수 있다. 가끔 예상치 못한 연관 관계나 새로운 추세가 발견되기도 해서 해당 문제를 더 잘 이해하도록 도와준다. 머신러닝 기술을 적용해서 대용량의 데이터를 분석하면 겉으로는 보이지 않던 패턴을 발견할 수 있다. 이를 데이터 마이닝 data mining라고 한다.

요약하면 머신러닝은 다음 분야에 뛰어나다.
- 기존 설루션으로는 많은 수동 조정과 규칙이 필요한 문제
- 전통적인 방식으로는 해결 방법이 없는 복잡한 문제
- 유동적인 환경
- 복잡한 문제와 대량의 데이터에서 통찰 얻기
1.3 애플리케이션 사례
- 생산 라인에서 제품 이미지를 분석해 자동으로 분류 : 합성곱 신경망 convolutional neural network
- 뇌를 스캔하여 종양 진단 : 시멘틱 분할 작업, CNN 이미지 각 픽셀 분류(종양의 정확한 위치와 모양을 결정)
- 자동으로 뉴스 기사 분류 : 자연어 처리 NLP natural language processing 작업 더 구체적으로 말하면 텍스트 분류이다. 순환 신경망 recurrent neural network RNN, CNN, 트랜스포머를 사용해 해결할 수 있다.
- 토론 포럼에서 부정적인 코멘트 분류 : NLP 도구 사용
- 긴 문서 요약 : 텍스트 요약이라 불리는 NLP의 한 분야
- 챗봇 또는 개인 비서 : 자연어 이해 NLU natural language understanding와 질문-대답 모듈을 포함한 여러 NLP 컴포넌트가 필요
- 다양한 성능 지표를 기반으로 수익 예측 : 회귀 regression 작업, 선형 회귀 linear regression, 다항 회귀 polynomial regression, 회귀 SVM, 회귀 랜덤 포레스트 random forest, 인공 신경망 artificial neural network과 같은 회귀 모델을 사용해서 해결할 수 있다. 지난 성능 지표의 시퀀스를 고려한다면 RNN, CNN 또는 트랜스포머를 사용한다.
- 음성 명령에 반응하는 앱 : 음성 인식 작업, 오디오 샘플을 처리해야 한다. RNN, CNN, 트랜스포머
- 신용카드 부정 거래 감지 : 이상치 탐지 작업
- 구매 이력 기반 고객별 집합 나누기 : 군집 clustering 작업
- 고차원의 복잡한 데이터를 의미있는 그래프로 표현 : 데이터 시각화 작업, 차원 축소 dimensionality reduction
- 구매 이력기반 관심 상품 추천 : 추천 시스템, 인공 신경망
- 지능형 게임 봇 : 강화 학습 RL reinforcement learning으로 해결한다.
1.4 머신러닝 시스템의 종류
- 사람의 감독하에 훈련하는 것인지 그렇지 않는 것인지(지도, 비지도, 준지도, 강화 학습)
- 실시간으로 점진적인 학습을 하는지 아닌지(온라인 학습과 배치 학습)
- 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 훈련 데이터셋에서 패턴을 발견하여 예측 모델을 만드는지(사례 기반, 모델 기반)
이 범주들은 서로 배타적이지 않으며 원하는 대로 연결할 수 있다.
1.4.1 지도 학습과 비지도 학습
머신러닝 시스템을 '학습하는 동안의 감독 형태나 정보량'에 따라 분류할 수 있다. 지도 학습, 비지도 학습, 준지도 학습, 강화 학습 등 네 가지 주요 범주가 있다.
지도 학습
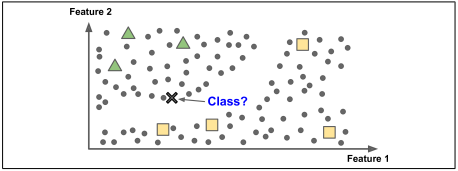
지도 학습 supervised learning 에는 알고리즘에 주입하는 훈련 데이터에 레이블 label 이라는 원하는 답이 포함된다.
분류 classification 가 전형적인 지도 학습 작업이며, 스팸 필터가 좋은 예이다. 스팸 필터는 많은 메일 샘플과 소속 정보로 훈련되어야 하며 어떻게 새 메일을 분류할지 학습해야 한다.

또 다른 전형적인 작업은 예측 변수 predictor variable 라 부르는 특성 feature 을 사용해 가격 같은 타깃 target 수치를 예측하는 것이다. 이런 종류의 작업을 회귀 regression 라고 부른다.
일부 회귀 알고리즘은 분류에 사용할 수도 있다. 반대로 분류 알고리즘을 회귀에 사용할 수도 있다. 예를 들어 분류에 널리 쓰이는 로지스틱 회귀는 클래스에 속할 확률을 출력한다.
주요 지도 학습 알고리즘들
- k-nearest neighbors, k-최근접 이웃
- linear regression, 선형 회귀
- logistic regression, 로지스틱 회귀
- support vector machine(SVM), 서포트 벡터 머신
- decision tree, random forest, 결정트리와 랜덤 포레스트
- neural networks, 신경망
비지도 학습
비지도 학습 unsupervised learning 에는 말 그대로 훈련 데이터에 레이블이 없다.

다음은 가장 중요한 비지도 학습 알고리즘이다.
- 군집 Clusting
- k-means
- DBSCAN
- 계층 군집 분석 hierarchical cluster analysis(HCA)
- 이상치 탐지 outlier detection, 특이치 탐지 novelty detection
- 원-클래스 one-class SMV
- 아이솔레이션 포레스트 isolation forest
- 시각화 visualization 차원 축소 dimensionality reduction
- 주성분 분석 principal component analysis(PCA)
- 커널 kernel PCA
- 지역적 선형 임베딩 locally-linear embediding LLE
- t-SNE t-destributed stochastic neighbor embedding
- 연관 규칙 학습 association rule learning
- 어프라이어리 Apriori
- 이클렛 Eclat
준지도 학습
준지도 학습 semisupervised learning은 일부만 레이블이 있는 데이터를 다룬다. 대부분의 준지도 학습은 지도 학습과 비지도 학습의 조합으로 이루어져 있다.
대부분의 준지도 학습 알고리즘은 지도 학습과 비지도 학습의 조합으로 이루어져 있다. 예를 들어 심층 신뢰 신경망 deep belief network, DBN 은 여러 겹으로 쌓은 제한된 볼츠만 머신 resticted Boltzmann machine, RBM 이라 불리는 비지도 학습에 기초한다. RBM이 비지도 학습 방식으로 순차적으로 훈련된 다음 전체 시스템이 지도 학습 방시긍로 세밀하게 조정된다.
강화 학습
강화 학습 reinforcement learning 은 매우 다른 종류의 알고리즘이다. 여기서는 학습 시스템을 에이전트라고 부르며 환경 environment 을 관찰해서 행동을 실행하고 그 결과로 보상 reward 혹은 벌점 penalty 를 받는다. 시간이 지나면서 가장 큰 보상을 얻기 위해 정책 policy 라고 부르는 최상의 전략을 스스로 학습한다. 정책은 주어진 상황에서 에이전트가 어떤 행동을 선택해야 할지 정의한다.
1.4.2 배치 학습과 온라인 학습
머신러닝 시스템을 분류하는 다른 기준은 입력 데이터의 스트림으로부터 점진적으로 학습할 수 있는지 여부이다.
배치 학습
배치 학습 batch learning 에는 시스템이 점진적으로 학습할 ㅅ수 없다. 가용한 데이터를 모두 사용해서 훈련시켜야 하고 이는 시간과 자원을 많이 소모한다. 먼저 시스템을 훈련시키고 그런 다음 제품 시스템에 적용하면 더 이상의 학습없이 실행된다. 즉, 학습한 것을 단지 적용만 한다. 이를 오프라인 학습 offline learning 라고 한다.
배치 학습 시스템이 새로운 데이터에 대해 학습하려면 새로운 데이터뿐만 아니라 이전 데이터도 포함한 전체 데이터를 사용하여 시스템의 새로운 버전을 처음부터 다시 훈련해야한다.
온라인 학습
온라인 학습 online learning 에서는 데이터를 순차적으로 한 개씩 또는 미니배치 mini-batch 라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킨다.
온라인 학습은 연속적으로 데이터를 받고 빠른 변화에 스스로 적응해야 하는 시스템에 적합하다.
온리안 학습 시스템에서 중요한 파라미터는 변화하는 데이터에 얼마나 빠르게 적응할 것인지이다. 이를 학습률 learning rate 라고 한다. 이를 높게 하면 시스템이 데이터에 빠르게 적응하지만 이전 데이터를 금방 잊어버리고, 낮을 경우 더 느리게 학습된다.
온라인 학습의 가장 큰 문제점은 시스템에 나쁜 데이터가 주입되었을 때 시스템 성능이 점진적으로 감소한다는 점이다.
1.4.3 사례 기반 학습과 모델 기반 학습
머신러닝 시스템은 어떻게 일반화 generalize 되는가에 따라 분류할 수 있다.대부분의 머신러닝 작업은 예측을 만드는 것이다. 이 말은 주어진 훈련 데이터로 학습하고 훈련 데이터에서는 본 적 없는 새로운 데이터에서 좋은 예측을 만들어야 한다는 뜻이다.
일반화를 위한 두 가지 접근법은 사례 기반 학습과 모델 기반 학습이다.
사례 기반 학습
가장 간단한 형태의 학습은 단순히 기억하는 것, 유사한 데이터를 구분하기 위해 유사도를 측정할 수도 있다. 이를 사례 기반 학습instnace-based learning 으로 시스템이 훈련 샘플을 기억함으로써 학습, 유사도 측정을 사용해 새로운 데이터와 학습한 샘플을 비교하는 식으로 일반화한다.
모델 기반 학습
샘플로부터 일반화시키는 다른 방법은 이 샘플들의 모델을 만들어 예측에 사용하는 것, 이를 모델 기반 학습model-based learning 이라고 한다.
선형 함수로 모델링하는 모델 선택, 이는 특성에 대한 선형 모델, 해당 모델은 특성에 대한 모델 파라미터를 가지고 이를 조정하여 선형 함수를 표현하는 모델을 얻을 수 있다.
모델을 사용하기 전에 이 파라미터를 정의해야 한다. 모델이 최상의 성능을 내도록 하는 값을 어떻게 알 수 있는지 판단하려면 측정 지표를 정해야 한다. 모델이 얼마나 좋은지 측정하는 호용 함수utility function,(또는 적합도 함수fitness function) 을 정의하거나 얼마나 나쁜지 측정하는 비용함수 cost function을 정의할 수 있다. 보통 선형 모델의 예측과 훈련 데이터 사이의 거리를 재는 비용 함수를 사용한다. 이 거리를 최소화 하는 것이 목표이다.
여기에서 선형 회귀 linear regression 알고리즘이 등장한다. 알고리즘에 훈련 데이터를 공급하면 데이터에 가장 잘 맞는 선형 모델의 파라미터를 찾는다. 이를 모델을 훈련 training 시킨다고 말한다.
이제 이 모델을 사용해 예측을 할 수 있다.
지금까지의 작업을 요약하면
- 데이터를 분석
- 모델 선택
- 훈련 데이터로 모델 훈련
- 새로운 데이터에 모델을 적용해 예측
이것이 전형적인 머신러닝 프로젝트의 형태
1.5 머신러닝의 주요 도전 과제
간단하게 말해 우리요 주요 작업은 학습 알고리즘을 선택해서 어떤 데이터에 훈련시키는 것이므로 문제가 될 수 있는 두 가지는 나쁜 알고리즘과 나쁜 데이터이다.
1.5.1 충분하지 않은 양의 훈련 데이터
대부분의 머신러닝 알고리즘이 잘 작동하려면 데이터가 많아야 한다.
| 믿을 수 없는 데이터의 효과 복잡한 문제에서 알고리즘보다 데이터가 더 중요하다는 이론의 존재  |
1.5.2 대표성 없는 훈련 데이터
일반화하기 원하는 새로운 사례를 훈련 데이터가 잘 대표하는 것이 중요, 일반화하려는 사례들을 대표하는 훈련 세틀르 사용하는 것이 매우 중요하지만, 어려운 문제이다.
샘플이 작으면 샘플링 잡음 sampling noise 이 생기고 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띠지 못 할 수도 있다. 이를 샘플링 편향 sampling bias 이라고 한다.
1.5.3 낮은 품질의 데이터
훈련 데이터가 에러, 이상치, 잡음으로 가득하다면 머신러닝 시스템이 내재된 패턴을 찾기 어려워 잘 작동하지 않을 것, 그렇기 때문에 훈련 데이터 정제에 시간을 투자할 가치가 높다. 대부분의 데이터 과학자들이 데이터 정제에 많은 시간을 쓰고 있다.
- 일부 샘플이 이상치라는 게 명확하면 간단히 그것들을 무시하거나 수동으로 잘못된 것을 고치는 것이 좋다.
- 일부 샘플에 특성 몇 개가 빠져있다면 이 특성을 모두 무시할지, 이 샘플을 무시할지, 빠진 값을 채울지 이 특성을 넣은 모델과 제외한 모델을 따로 훈련시킬 것인지 결정해야 한다.
1.5.4 관련 없는 특성
훈련 데이터에 관련 없는 특성이 적고 관련 있는 특성이 충분해야 시스템이 학습할 수 있다. 성공적인 머신러닝 프로젝트의 핵심 요소는 훈련에 사용할 좋은 특성들을 찾는 것이다. 이 과정을 특성 공학 feature engineering이라 한다.
- 특성 선택 feature selection : 가지고 있는 특성 중 훈련에 가장 유용한 특성을 선택한다.
- 특성 추출 feature extraction : 특성을 결합하여 더 유용한 특성을 만든다. 차원 축소 알고리즘이 도움이 될 수 있다.
- 새로운 데이터를 수집해 새 특성을 만든다
1.5.5 훈련 데이터 과대적합
과도한 일반화한 것을 과대적합overfitting이라고 한다. 모델이 훈련 데이터에 너무 잘 맞으면 일반성이 떨어진다는 것
훈련 세트에 잡음이 많거나 데이터셋이 너무 작으면 잡음이 섞인 패턴을 감지하게 된다. 당연히 이런 패턴은 새로운 샘플에 일반화되지 못한다.
모델을 단순하게 하고 과대적합의 위험을 감소시키기 위해 모델에 제약을 가하는 것을 규제 refularization라고 한다. 선형 모델은 두 개의 모델 파라미터를 가지고 있고, 이는 훈련 데이터에 모델을 맞추기 위한 두 개의 자유도 degree of freedom 를 학습 알고리즘에 부여한다. 모델은 직선의 절편과 기울기를 조절할 수 있다. 이 값을 0이 되도록 강제하면 알고리즘에 한 개의 자유도만 남게 되고 데이터에 적절하게 맞춰지기 힘들 것이다. 즉, 할 수 있는 것이 훈련 데이터에 가능한 한 가깝게 되도록 직선을 올리거나 내리는 것이 전부이므로 결국 평균 근처가 된다.
알고리즘이 이 파라미터를 수정하도록 허락하되 작은 값을 갖도록 유지시키면 학습 알고리즘이 자유도 1과 2 사이의 적절한 어딘가에 위치할 것이다. 이는 자유도가 2인 모델보다는 단순하고 1보다는 복잡한 모델을 만든다. 올바른 균형을 찾는 것이 중요
학습하는 동안 적용할 규제의 양은 하이퍼파라미터 hyperparameter 가 결정한다. 학습 알고리즘의 파라미터로 알고리즘으로부터 영향을 받지 않고, 훈련 전에 미리 지정되고, 훈련하는 동안 상수로 남아 있다.

1.5.6 훈련 데이터 과소적합
모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 일어난다.
- 모델 파라미터가 더 많은 강력한 모델을 선택
- 학습 알고리즘에 더 좋은 특성을 제공
- 모델의 제약을 줄인다.
1.5.7 정리하자면
- 머신런닝은 명시적인 규칙을 코딩하지 않고 기계가 데이터로부터 학습하여 어떤 작업을 더 잘하도록 만드는 것
- 지도 학습과 비지도 학습, 배치 학습과 온라인 학습, 사례 기반 학습과 모델 기반 학습
- 머신러닝 프로젝트에서는 훈련 세트에 데이터를 모아 학습 알고리즘에 주입, 학습 알고리즘이 모델 기반이면 훈련 세트에 모델을 맞추기 위해 모델 파라미터를 조정하고 새로운 데이터에서도 좋은 예측을 만들거라 기대, 사례 기반이면 샘플을 기억하는 것이 학습이고 유사도 측정을 사용하여 학습한 샘플과 새로운 샘플을 비교하는 식으로 샘플에 일반화한다.
- 훈련 세트가 너무 작거나 대표성이 없거나 잡음이 많고 관련 없는 특성으로 오염되어 있다면 시스템이 잘 작동하지 않는다. 너무 단순하거나 너무 복잡하지 않아야 한다.
1.6 테스트와 검증
모델이 새로운 샘플에 얼마나 잘 일반화할 지 아는 방법은 새로운 샘플에 실제로 적용하는 것
훈련 데이터를 훈련 세트와 테스트 세트로 나누어 훈련 세트를 사용해 모델을 훈련, 테스트 세트를 사용해 모델을 테스트한다.
새로운 샘플에 대한 오류 비율을 일반화 오차 generalization error 또는 외부 샘플 오차 out-of-sample error 라고 한다. 테스트 세트에서 모델을 평가함으로써 이 오차에 대한 추정값estimation을 얻는다 .이 값은 이전에 본 적 없는 새로운 샘플에 모델이 얼마나 잘 작동할지 알려준다.
1.6.1 하이퍼파라미터 튜닝과 모델 선택
일반화 오차를 테스트 세트에서 여러 번 측정할 경우 모델과 하이퍼파라미터가 테스트 세트에 최적화된 모델을 만들고, 이는 모델이 새로운 데이터에 잘 작동하지 않을 수 있다.
이 문제에 대한 일반적인 해결 방법은 홀드아웃 검증 holdout validation 으로 훈련 세트의 일부를 떼어 내어 여러 후보 모델을 평가하고 가장 좋은 하나를 선택한다. 이 홀드 아웃 세트를 검증 세트 validation set라고 부른다.
줄어든 훈련 세트에서 다양한 하이퍼파라미터 값을 가진 여러 모델을 훈련한다. 그다음 검증 세트에서 가장 높은 성능을 내는 모델을 선택한다. 검증 과정이 끝나면 이 최선의 모델을 전체 훈련 세트에서 다시 훈련하여 최종 모델을 만든다. 마지막으로 최종 모델을 테스트 세트에서 평가하여 일반화 오차를 추정한다.
검증 세트가 작다는 문제가 발생, 이 문제를 해결하기 위해 교차 검증 cross-validation 을 수행, 교차 검증을 통해 검증 세트가 작거나 너무 큰 문제를 해결하지만 검증 세트 개수에 비례해 훈련 시간이 늘어난다.
데이터 불일치
훈련 데이터가 실제 제품에 사용될 데이터를 완벽하게 대표하지 못할 수 있다. 이 경우 가장 중요한 규칙은 검증 세트와 테스트 세트가 실전에서 기대하는 데이터를 가능한 한 잘 대표해야 한다. 따라서 검증 세트와 테스트 세트에 대표 사진이 배타적으로 포함되어야 한다.
이 방법으로 훈련 사진의 일부를 떼어내어 또 다른 세트를 만드는 것으로 훈련 개발 세트 train-dev set 라고 부른다.
모델을 훈련한 다음 훈련-개발 세트에서 평가한다. 모델이 잘 작동한다면 훈련 세트에 과대적합된 것이 다니다. 이 모델이 검증 세트에서 나쁜 성능을 낸다면 이 문제는 데이터 불일치에서 오는 것이다. 반대로 모델이 훈련-개발 세트에서 잘 작동하지 않느다면 이는 훈련 세트에 과대적합된 것이다.
따라서 모델을 규제하거나 더 많은 훈련 데이터를 모으거나 훈련 데이터 정제를 시도해야한다.
1.7 연습 문제
- 머신러닝을 어떻게 정의할 수 있나요?
머신러닝은 데이터로부터 학습할 수 있는 시스템을 만드는 것, 학습이란 어떤 작업에서 주어진 성능 지표가 더 나아지는 것을 의미
- 머신러닝이 도움을 줄 수 있는 문제 유형 네 가지
명확한 해결책이 없는 복잡한 문제, 수작업으로 긴 규칙 리스트를 대체하는 경우, 변화하는 환경에 적응하는 시스템을 만드는 경우, 사람에게 통찰력을 제공해야 하는 경우
- 레이블된 훈련 세트란 무엇인가?
레이블된 훈련 세트는 각 샘플에 대해 원하는 정답을 담고 있는 훈련 세트
- 가장 널리 사용되는 지도 학습 작업 두 가지는 무엇인가요?
회귀와 분류
- 보편적인 비지도 학습 작업 네 가지는 무엇인가요?
군집, 시각화, 차원 축소, 연관 규칙 학습
- 사전 정보가 없는 여러 지형에서 로봇을 걸어가게 하려면 어떤 종류의 머신러닝 알고리즘을 사용할 수 있나요?
강화 학습
- 고객을 여러 그룹으로 분할하려면 어떤 알고리즘을 사용해야 하나요?
그룹 정의를 위해 군집 알고리즘을 사용할 수 있고, 그룹이 존재한다면 분류 알고리즘으로 각 그룹에 대한 샘플 주입
- 스팸 감지의 문제는 지도 학습과 비지도 학습 중 어떤 문제로 볼 수 있나요?
지도 학습 문제
- 온라인 학습 시스템이 무엇인가요?
점진적으로 학습하는 시스템, 변화하는 데이터와 자율 시스템에 빠르게 적응하고 매우 많은 양의 데이터를 훈련시킬 수 있다.
- 외부 메모리 학습이 무엇인가요?
대용량의 데이터를 다루는 학습, 데이터를 미니배치로 나누고 온라인 학습 기법을 사용
- 예측을 하기 위해 유사도 측정에 의존하는 학습 알고리즘은 무엇인가요?
사례 기반 학습 시스템, 훈련 데이터를 기억하는 학습, 새로운 샘플이 주어지면 유사도 측정을 통해 학습된 샘플 중에서 가장 비슷한 것을 찾아 예측으로 사용
- 모델 파라미터와 학습 알고리즘의 하이퍼파라미터 사이에는 어떤 차이가 있나요?
모델은 하나 이상의 파라미터를 사용해 새로운 샘플이 주어지면 무엇을 예측할지 결정한다. 학습 알고리즘은 모델이 새로운 샘플에 잘 일반화되도록 이런 파라미터들의 최적값을 찾는다. 하이퍼파라미터는 모델이 아니라 이런 학습 알고리즘 자체의 파라미터
- 모델 기반 알고리즘이 찾는 것은 무엇인가요? 성공을 위해 이 알고리즘이 사용하는 가장 일반적인 전략은 무엇인가요? 예측은 어떻게 만드나요?
모델 기반 학습 알고리즘은 새로운 샘플에 잘 일반화되기 위해 모델 파라미터의 최적값을 찾는다. 일반적으로 훈련 데이터에서 시스템의 예측이 얼마나 나쁜지 측정하고 모델에 규제가 있다면 모델 복잡도에 대한 페널티를 더한 비용 함수를 최소화함으로써 시스템을 훈련시킨다. 예측을 만들려면 학습 알고리즘이 찾은 파라미터를 사용하는 모델의 예측 함수에 새로운 샘플의 특성을 주입한다.
- 머신러닝의 주요 도전 과제는 무엇인가요?
부족한 데이터, 낮은 데이터 품질, 대표성 없는 데이터, 무의미한 특성, 과소 과대 적합
- 모델이 훈련 데이터에서의 성능은 좋지만 새로운 샘플에서의 일반화 성능이 나쁘다면 어떤 문제가 있는 건가요? 가능한 해결책 세 가지는 무엇인가요?
훈련 데이터에서 과대적합되었을 가능성 더 많은 데이터를 모으거나, 모델을 단순화, 규제, 잡음 감소
- 테스트 세트가 무엇이고 왜 사용해야 하나요?
모델이 새로운 샘플에 대해 만들 일반화 오차를 추정하기 위해 사용
- 검증 세트의 목적은 무엇인가요?
모델을 비교하는데 사용, 가장 좋은 모델을 고르고 하이퍼파라미터를 튜닝
- 훈련-개발 세트가 무엇인가요? 언제 필요하고 어떻게 사용해야 하나요?
훈련-개발 세트는 검증, 테스트 세트에 사용되는 데이터와 훈련 세트 사이에 데이터 불일치 위험이 있을 때 사용, 훈련 세트에서의 훈련, 검증 세트에서 평가
- 테스트 세트를 사용해 하이퍼파라미터를 튜닝하면 어떤 문제가 생기나요?
과대적합될 위험이 있고 일반화 오차에 대해 낙관적으로 측정
'책 > Hands-On Machine Learning' 카테고리의 다른 글
| 6. 결정 트리 (0) | 2022.10.07 |
|---|---|
| 5.서포트 벡터 머신(SVM) (0) | 2022.10.07 |
| 4. 모델 훈련 (0) | 2022.10.07 |
| 3. 분류 (1) | 2022.10.07 |
| 2. 머신러닝 프로젝트 처음부터 끝까지 (0) | 2022.10.06 |



