3.2 AE - 오토인코더 AutoEncoder
- 인코더 : 네트워크는 고차원 입력 데이터를 저차원 표현 벡터로 압축
- 디코더 : 네트워크는 주어진 표현 벡터를 원본 차원으로 다시 압축 해제
입력데이터(그림) - 인코더 ( 표현 벡터, 좌표 ) - 디코더(재구성 그림)
입력과 재구성 사이의 손실을 최소화하는 인코더와 디코더의 가중치를 찾기 위해 네트워크가 훈련된다.
표현 벡터는 원본 이미지를 저차원 잠재 공간으로 압축한 것, 잠재 공간의 어떤 포인트를 선택해도 디코더에 이 포인트를 통과시켜서 새로운 이미지를 생성할 수 있다. 디코더는 잠재 공간의 포인터를 이미지로 변환하는 방법을 학습하기 때문
앞선 비유에서느 2차원 잠재 공간 안의 표현 벡터를 사용해 이미지를 인코딩,
인코더를 학습하여 잠재 공간 안에 랜덤한 잡음을 나타내기 어렵기 때문에 AE는 이미지에서 잡음을 제거하기 위해 사용될 수 있다. 이와 같은 작업에서는 2차원 잠재 공간은 입력으로부터 의미 있는 정보를 충분히 인코딩하기에 작을 것, 잠재 공간의 차원이 증가하면 AE를 생성 모델로 사용하는 데 금방 문제가 발생
3.2.1 첫번째 AE
모델 정의 클래스를 별도의 파일로 생성, 매개변수를 사용해 특정 모델 구조를 정의하여 Autoencoder 객체를 만들 수 있다.
AE = Autoencoder(
input_dim = (28,28,1)
, encoder_conv_filters = [32,64,64, 64]
, encoder_conv_kernel_size = [3,3,3,3]
, encoder_conv_strides = [1,2,2,1]
, decoder_conv_t_filters = [64,64,32,1]
, decoder_conv_t_kernel_size = [3,3,3,3]
, decoder_conv_t_strides = [1,2,2,1]
, z_dim = 2
)3.2.2 인코더
AE 에서 인코더가 하는 일은 입력 이미지를 잠재 공간의 한 포인트로 매핑하는 것, 인코더의 구조
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
encoder_input (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
encoder_conv_0 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
encoder_conv_1 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
encoder_conv_2 (Conv2D) (None, 7, 7, 64) 36928
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 7, 7, 64) 0
_________________________________________________________________
encoder_conv_3 (Conv2D) (None, 7, 7, 64) 36928
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 7, 7, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 3136) 0
_________________________________________________________________
encoder_output (Dense) (None, 2) 6274
=================================================================
Total params: 98,946
Trainable params: 98,946
Non-trainable params: 0
_________________________________________________________________먼저 입력 층을 만들어 이미지를 입력받고 차례대로 4개의 Conv2D 층을 통과시키면서 점점 고수준의 특성을 잡아낸다. 일부 합성곱 층은 스트라이드 2를 사용해 출력의 크기를 줄인다. 마지막 합성곱 층의 출력은 Flatten 층을 통해 펼쳐지고 2차원 잠재 공간을 표현하기 위해 크기가 2인 Dense 층에 연결된다.
다음은 Autoencoder 클래스의 _build() 메서드 코드, 이 메서드는 Autoencoder 클래스의 객체가 생성될 때 자동으로 호출된다.
encoder_input = Input(shape=self.input_dim, name='encoder_input')
x = encoder_input
for i in range(self.n_layers_encoder):
conv_layer = Conv2D(
filters = self.encoder_conv_filters[i],
kernel_size = self.encoder_conv_kernel_size[i],
strides = self.encoder_conv_strides[i],
padding = 'same',
name = 'encoder_conv_' + str(i)
)
x = conv_layer(x)
x = LeakyReLU()(x)
shape_before_flattening = K.int_shape(x)[1:]
x = Flatten()(x)
encoder_output = Dense(self.z_dim, name='encoder_output')(x)
self.encoder = Model(encoder_input, encoder_output)인코더의 입력을 정의, 합성곱 층을 차례대로 쌓는다, 마지막 합성곱 층을 하나의 벡터로 펼친다. Dense 층을 사용해 이 벡터를 2차원 잠재 공간으로 연결한다(self.z_dim의 값은 앞의 예제에서 z_dim 매개변수로 받은 값), 인코더를 정의하는 케라스 모델을 생성, 이 모델은 입력 이미지를 받아 2D 잠재 공간으로 인코딩한다.
인코더에 있는 합성곱 층 개수를 간단하게 바꿀 수 있다. 모델 구조를 정의하는 리스트에 원소를 추가하거나 제거하면 된다.
3.2.3 디코더
디코더는 인코더의 반대, 전치 합성곱 층을 사용 convolutional transpose
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
decoder_input (InputLayer) (None, 2) 0
_________________________________________________________________
dense_1 (Dense) (None, 3136) 9408
_________________________________________________________________
reshape_1 (Reshape) (None, 7, 7, 64) 0
_________________________________________________________________
decoder_conv_t_0 (Conv2DTran (None, 7, 7, 64) 36928
_________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 7, 7, 64) 0
_________________________________________________________________
decoder_conv_t_1 (Conv2DTran (None, 14, 14, 64) 36928
_________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
decoder_conv_t_2 (Conv2DTran (None, 28, 28, 32) 18464
_________________________________________________________________
leaky_re_lu_7 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
decoder_conv_t_3 (Conv2DTran (None, 28, 28, 1) 289
_________________________________________________________________
activation_1 (Activation) (None, 28, 28, 1) 0
=================================================================
Total params: 102,017
Trainable params: 102,017
Non-trainable params: 0
_________________________________________________________________완전한 반대 구조를 가질 필요 없이, 디코더의 마지막 층의 출력이 인코더의 입력 크기와 같기만 하면 된다.(손실 함수가 픽셀 단위로 비교하기 때문)
전치 합성곱 층
표준 합성곱 층은 strides = 2로 설정했을 때 입력 텐서의 높이와 너비를 모두 절반으로 줄인다.
전치 합성곱 층은 표준 합성곱 층의 원리와 동일하지만 strides = 2로 설정했을 때 텐서의 높이와 너비를 두 배로 늘린다.
케라스에서는 Conv2DTranspose 층을 사용하여 전치 합성곱 연산을 수행할 수 있다. 스트라이드 2로 Conv2DTranspose 층을 쌓으면 각 층에서 점진적으로 크기가 증가되어 원본 이미지 차원을 되돌릴 수 있다.
디코더의 케라스 소스
decoder_input = Input(shape=(self.z_dim), name='decoder_input')
x = Dense(np.prod(shape_before_flattening))(decoder_input)
x = Reshape(shape_before_flattening)(x)
for i in range(self.n_layers_decoder):
conv_layer = Conv2DTranspose(
filters = self.decoder_conv_filters[i],
kernel_size = self.decoder_conv_kernel_size[i],
strides = self.decoder_conv_strides[i],
padding = 'same',
name = 'decoder_conv_' + str(i)
)
x = conv_t_layer(x)
if i < self.n_layers_decoder - 1:
x = LeakyReLU()(x)
else:
x=Activation('sigmoid')(x)
decoder_output = x
self.decoder = Model(decoder_input, decoder_output)디코더의 입력을 정의한다. 입력을 Dense 층에 연결한다.(shape_before_flattening은 마지막 합성곱 층의 출력 크기를 담고 있는 텐서이다. np.prod 함수를 통해 배열의 원소 곱을 시행) 이 결과를 전치 합성곱 층에 주입할 수 있도록 벡터를 다차원 텐서로 바꾼다. 전치 합성곱을 차례대로 쌓는다. 디코더를 정의하는 케라스 모델의 생성, 이 모델은 잠재 공간의 한 포인트를 받아 원본 이미지 차원으로 디코딩한다.
3.2.4 인코더와 디코더 연결
인코더와 디코더를 동시에 훈련하기 위해 입력 이미지가 인코더를 지나 디코더로 나오는 모델을 만들어야 한다.
model_input = encoder_input
model_output = decoder(encoder_output)
self.model = Model(model_input, model_output)1: AE의 입력은 인코더의 입력과 같다
2: AE의 출력은 디코더의 출력, 디코더는 인코더의 출력을 입력으로 받는다.
3: 완전한 AE를 정의한 케라스 모델, 이 모델은 이미지를 받아 인코더와 디코더를 통과시켜 원본 이미지의 재구성을 생성
모델의 정의 후 손실 함수와 옵티마이저를 연결해야 한다. 손실 함수는 원본 이미지와 재구성의 개별 픽셀에 대해 평균 제곱근 오차 root mean squared error 나 이진 크로스 엔트로피를 보통 사용, 이진 크로스 엔트로피는 극단적으로 나쁜 예측에 큰 벌칙을 부여하기 때문에 픽셀 예측값을 중간 범위로 만드는 경향이 있다. 이런 이유로 RMSE가 선호, 이후 입력 이미지를 입력과 출력으로 제공하여 AE를 훈련한다.(AE는 입력을 재구성하는 거이 목적이므로 입력 자체가 타깃이 된다. 이런 종류의 학습 방법을 자기 지도 학습 self super vised learning 이라고도 부른다.)
optimizer = Adam(lr=learning_rate)
def r_loss(y_true, y_pred):
return K.mean(K.square(y_true - y_pred), axis = [1,2,3])
self.model.compile(optimizer = optmizer, loss = r_loss)
self.model.fit(
x = x_train,
y = x_train,
batch_size = batch_size,
shuffle = True,
epochs = 10,
callbacks = callbacks_list
)
 |
 |
표현된 잠재 공간을 확인해보면 몇 가지 점을 확인할 수 있다.
1. 포인트에 대칭이거나 값이 제한되어 있지 않다.
2. 어떤 숫자는 매우 작은 영역에 밀집되어 있다.
3. 색깔 사이에는 간격이 크고 숫자가 거의 없다.
잠재 공간에서 랜덤한 포인트를 선택해 디코더를 통과시킨 후 실제와 같은 숫자 이미지를 얻는 것이 목표로 이를 여러 번 실행했을 때 여러 종류의 숫자가 비슷한 횟수로 출력되기를 기대한다.
하지만 잠재 공간의 포인트 분포가 정의되지 않아. 잠재 공간 샘플링의 문제가 있다.
또한 생성되는 이미지의 다양성이 부족하고 마지막으로 생성된 이미지의 품질이 나쁘다느 ㄴ것을 볼 수 있다.
2차원에서는 이러한 문젤ㄹ 감지하기 어렵다. AE의 차원이 적기 대문에 잠재 공간에 숫자를 조밀하게 채울 수 잇고 숫자 그룹간의 간격이 상대적으로 작다. 하지만 복잡한 이미지를 생성하기 위해 잠재 공간에 차원을 추가하기 시작하면 이러한 문제는 더욱 심화될 것이다.
이런 문제를 어떻게 해결할 수 있을까?
3.4 VAE 만들기
AE를 VAE로 바꾸어 이를 해결한 생성 모델을 만들 수 있다. 바꿔야 할 부분은 인코더와 손실 함수 이다.
3.4.1 인코더
AE에서는 각 이미지가 잠재 공간의 한 포인트에 직접 매핑된다. VAE는 각 이미지가 잠재 공간에 있는 포인트 주변의 다변수 정규 분포 multivariate normal distribution 에 매핑된다.
정규 분포
정규 분포 normal distribution 는 종 모양의 곡선을 가진 확률 분포이다. 1차원일 때는 평균과 분산 2개의 변수로 정의된다. 표준 편차는 분산의 제곱근이다.
1차원 정규 분포의 확률 밀도 함수 probability density function 는 다음과 같다.

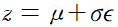
정규 분포 개념을 1차원 이상으로 확장할 수 있다. 일반적인 k 차원 다변수 정규 분포에 대한 확률 밀도 함수는 다음과 같다.


VAE는 잠재 공간 차원 사이에는 어떤 상관관계가 없다고 가정한다. 따라서 공분산 행렬은 대각 행렬이 된다. (두 변수가 독립이면 상관 계수는 0이 되기 때문) 이는 인코더가 각 입력을 평균 벡터와 분산 벡터에만 매핑할 필요가 있다는 것을 뜻한다. 차원 간의 공분산에 대해 신경 쓸 필요가 없다.
신경망 유닛의 일반적인 출력은 모든 실수지만 분산은 항상 양수이기 대문에 분산에 로그를 취한 값에 매핑한다.
요약하면, 인코더는 입력 이미지를 받아 잠재 공간의 다변수 정규 분포를 정의하는 2개의 벡터 mu와 log_var로 인코딩한다.
mu : 이 분포의 평균 벡터, log_var : 차원별 분산의 로그값
이미지를 잠재 공간의 특정 포인트 z로 인코딩하기 위해 다음 식을 사용해 분포에서 샘플링을 한다.
z = mu + sigma * epsilon
sigma = exp(log_var/2)epsilon은 표준 정규 분포에서 샘플링된 값이다.
이전에는 잠재 공간을 연속적으로 만들 필요가 없었다. 포인트가 제대로 된 숫자의 이미지로 디코딩하더라도 주변의 포인트가 비슷해야 할 필요가 없다. 이제는 mu 주변의 지역에서 랜덤한 포인트를 샘플링하기 때문에 디코더는 재구성 손실이 작게 유지되도록 같은 영역에 위치한 포인트를 매우 비슷한 이미지로 디코딩해야 한다. 잠재 공간에서 디코더가 본 적 없는 포인트를 선택하더라도 제대로 된 이미지를 디코딩할 수 있는 성질
VAE 인코더 VariationalAutoencoder 클래스의_build메서드 코드
encoder_input = Input(shape=self.input_dim, name='encoder_input')
x = encoder_input
for i in range(self.n_layers_encdoer):
conv_layer = Conv2D(
filters = self.encoder_conv_filters[i],
kernel_size = self.encoder_conv_kernel_size[i],
strides = self.encoder_conv_strides[i],
padding = 'same',
name = 'encoder_conv_' + str(i)
)
x = conv_layer(x)
if self.use_batch_norm:
x = BatchNormalization()(x)
x = LeakyReLU()(x)
if self.use_dropout:
x = Dropout(rate = 0.25)(x)
shape_before_flattening = K.int_shape(x)[1:]
x = Faltten()(x)
self.mu = Dense(self.z_dim, name='mu')(x)
self.log_var = Dense(self.z_dim, name='log_var')(x)
encoder_mu_log_var = Model(encoder_input, (self.mu, self.log_var))
def sampling(args):
mu, log_var = args
epsilon = K.random_normal(shape=K.shape(mu), mean=0., stddev=1.)
return mu + K.exp(log_var/2)*epsilon
encoder_output = Lambda(sampling, name='encoder_output')([self.mu, self.log_var])
encoder = Model(encoder_input, encoder_output)1. Flatten 층을 바로 2차원 잠재 공간에 연결하지 않고 mu 층과 log_var 층에 연결한다.
2. 이 케라스 모델은 이미지가 입력되면 mu와 log_var 의 값을 출력한다.
3. Lambda 층이 잠재 공간에서 mu와 log_var로 정의되는 정규분포로부터 포인트 z를 샘플링한다.
4. 인코더를 정의하는 케라스 모델을 만든다. 이 모델은 입력 이미지를 받아 mu와 log_var 로 정의된 정규 분포에서 한 포임트를 샘플링하여 2차원 잠재 공간으로 인코딩한다.
3.4.2 손실 함수
이전 손실 함수는 원본 이미지와 인코더와 디코더를 통과한 재구성 사이의 RMSE 손실로만 구성되었다. 이를 재구성 손실 reconstruction loss 라고 하며 VAE 에도 사용된다. VAE는 추가적으로 콜백-라이블러리 발산 kullback-Leibler divergence을 사용한다.
KL 발산은 학 확률 분포가 다른 분포와 얼마나 다른지를 측정하는 도구이다. VAE에서 평균이 mu이고 분산이 log_var인 정규 분포가 표준 정규 분포와 얼마나 다른지를 측정해야 한다. 이런 경우 KL 발산은 다음과 같이 계산된다.
kl_loss = -0.5 * sum(1 + log_var - mu^2 - exp(log_var))

이 식의 덧셈은 잠ㅈ재 공간의 모든 차원에 대해서 수행된다. 모든 차원의 mu, log_var = 0 일 때 kl_loss가 최소이다. 두 항이 0에서 멀어지면 kl_loss 는 증가한다.
요약하면, KL 발산 항은 샘플을 표준 정규 분포에서 크게 벗어난 mu와 log_var 변수로 인코딩하는 네트워크에 벌칙을 가한다.
왜 손실 함수에서 KL 발산 항을 추가하는 것이 도움이 될까? 첫째, 잠재 공간에서 포인트를 선택할 때 사용할 수 있는 잘 정의된 분포를 가지게 된다. 이 분포에서 샘플링하면 VAE가 바라보고 있는 영역 안의 포인트를 선택할 가능성이 매우 높다. 둘째, 이 항이 모든 인코딩된 분포를 표준 정규 분포에 가깝게 되도록 강제한다. 이로 인해 포인트 군집 사이에 큰 간격이 생길 가능성이 적다. 대신 인코더는 원점 주변의 공간을 대칭적이고 효과적으로 사용하려고 한다.
코드에서 VAE 손실 함수는 단순히 재구성 손실과 KL 발산 손시 항을 더한 것이다. 재구성 손실 항에 r_loss_factor 로 가중치를 주어 KL 발산 손실과 균형을 맞추게 하였다. 재구성 손실에 가중치를 너무 크게 주면 KL 손실이 만족할 만한 규제 효과를 내지 못하고 보통의 AE 에서 보았던 문제를 다시 겪게 될 것이다. 재구성 손실의 가중치가 너무 작으면 KL 발산 손실에 압도되어 재구성 이미지 품질이 나빠진다. 이 가중치는 VAE 를 훈련할 때 튜닝해야 할 파라미터 중 하나이다.
optimizer = Adam(lr=learning_rate)
def vae_r_loss(y_true, y_pred):
r_loss = K.mean(K.square(y_true - y_pred), axis = [1,2,3])
return r_loss_factor * r_loss
def vae_kl_loss(y_true, y_pred):
kl_loss = -0.5 * K.sum(1 + self.log_var - K.square(self.mu) - K.exp(self.log_var), axis = 1)
return kl_loss
def vae_loss(y_true, y_pred):
r_loss = vae_r_loss(y_true, y_pred)
kl_loss = vae_kl_loss(y_true, y_pred)
return r_loss + kl_loss
optimizer = Adam(lr=learning_rate)
self.model.compile(optimizer=optimizer, loss=vae_loss, metrics=[vae_r_loss, vae_kl_loss])3.4.3 VAE 분석

표준 정규 분포에서 샘플링하여 이 공간에서 디코딩할 새로운 포인트를 생성할 수 있다.
그다음 잘못된 형태로 생성된 숫자가 적다. 인코더가 결정적이지 않고 확률적이므로 잠재 공간이 국부적으로 연속적이다.
마지막으로 어느 한 숫자가 우세하지 않다. 그래프에서 색깔마다 거의 비슷한 영역을 차지하고 있다.
3.5 VAE를 사용한 얼굴 이미지 생성
얼굴 컬러 이미지 200,00 개를 모아 놓은 것, 각 샘플은 여러 가지 레이블을 가진다. 물론 VAE를 훈련할 때 레이블이 필요하진 않지만 나중에 다차원 잠재 공간에 어떻게 특성이 감지되었는지 탐색할 때 레이블을 사용한다. VAE가 훈련되고 나면 잠재 공간에서 샘플링하여 새로운 얼굴을 생성할 수 있다.
3.5.1 VAE 훈련
- 이 데이터의 입력 채널은 1개가 아닌 3개(RGB) 이다. 따라서 디코더의 마지막에 있는 전치 합성곱 층의 채널의 수를 바꿔야 한다.
- 사용할 잠재 공간의 차원 수는 2개가 아닌 200개이다. 이미지에 있는 상세 정보를 충분히 인코딩하기 위해 잠재 공간의 차원을 늘렸다.
- 훈련 속도를 높이기 위해 각 합성곱 층 위에 배치 정규화 층을 둔다.
- 재구성 손실 가중치 파라미터를 10,000으로 증가시킨다. 이 파라미터는 튜닝이 필요하기 때문에 이 데이터셋과 이 네트워크 구조에서 좋은 성능을 내는 값을 찾은 것,
- 이미지를 VAE로 주입한다.
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
encoder_input (InputLayer) (None, 128, 128, 3) 0
__________________________________________________________________________________________________
encoder_conv_0 (Conv2D) (None, 64, 64, 32) 896 encoder_input[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 64, 64, 32) 128 encoder_conv_0[0][0]
__________________________________________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 64, 64, 32) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 64, 64, 32) 0 leaky_re_lu_1[0][0]
__________________________________________________________________________________________________
encoder_conv_1 (Conv2D) (None, 32, 32, 64) 18496 dropout_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 32, 32, 64) 256 encoder_conv_1[0][0]
__________________________________________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 32, 32, 64) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
dropout_2 (Dropout) (None, 32, 32, 64) 0 leaky_re_lu_2[0][0]
__________________________________________________________________________________________________
encoder_conv_2 (Conv2D) (None, 16, 16, 64) 36928 dropout_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 16, 16, 64) 256 encoder_conv_2[0][0]
__________________________________________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 16, 16, 64) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
dropout_3 (Dropout) (None, 16, 16, 64) 0 leaky_re_lu_3[0][0]
__________________________________________________________________________________________________
encoder_conv_3 (Conv2D) (None, 8, 8, 64) 36928 dropout_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 8, 8, 64) 256 encoder_conv_3[0][0]
__________________________________________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 8, 8, 64) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
dropout_4 (Dropout) (None, 8, 8, 64) 0 leaky_re_lu_4[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 4096) 0 dropout_4[0][0]
__________________________________________________________________________________________________
mu (Dense) (None, 200) 819400 flatten_1[0][0]
__________________________________________________________________________________________________
log_var (Dense) (None, 200) 819400 flatten_1[0][0]
__________________________________________________________________________________________________
encoder_output (Lambda) (None, 200) 0 mu[0][0]
log_var[0][0]
==================================================================================================
Total params: 1,732,944
Trainable params: 1,732,496
Non-trainable params: 448
__________________________________________________________________________________________________
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
decoder_input (InputLayer) (None, 200) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 823296
_________________________________________________________________
reshape_1 (Reshape) (None, 8, 8, 64) 0
_________________________________________________________________
decoder_conv_t_0 (Conv2DTran (None, 16, 16, 64) 36928
_________________________________________________________________
batch_normalization_5 (Batch (None, 16, 16, 64) 256
_________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 16, 16, 64) 0
_________________________________________________________________
dropout_5 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
decoder_conv_t_1 (Conv2DTran (None, 32, 32, 64) 36928
_________________________________________________________________
batch_normalization_6 (Batch (None, 32, 32, 64) 256
_________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 32, 32, 64) 0
_________________________________________________________________
dropout_6 (Dropout) (None, 32, 32, 64) 0
_________________________________________________________________
decoder_conv_t_2 (Conv2DTran (None, 64, 64, 32) 18464
_________________________________________________________________
batch_normalization_7 (Batch (None, 64, 64, 32) 128
_________________________________________________________________
leaky_re_lu_7 (LeakyReLU) (None, 64, 64, 32) 0
_________________________________________________________________
dropout_7 (Dropout) (None, 64, 64, 32) 0
_________________________________________________________________
decoder_conv_t_3 (Conv2DTran (None, 128, 128, 3) 867
_________________________________________________________________
activation_1 (Activation) (None, 128, 128, 3) 0
=================================================================
Total params: 917,123
Trainable params: 916,803
Non-trainable params: 320
_________________________________________________________________인코더와 디코더의 구조
3.5.2 VAE 분석
VAE를 만드는 목적이 완벽한 재구성 손실을 달성하려는 것이 아니다. 최종 목적은 잠재 공간으로부터 샘플링하여 새로운 얼굴 이미지를 생성하는 것이다.
이를 위해 잠재 공간의 포인트 분포가 다변수 표준 정규 분포와 비슷하지 확인해야 한다. 모든 차원을 동시에 볼 수 업기 때문에 잠재 공간의 차원마다 개별적으로 분포를 확인한다. 어떤 차원이 표준 정규 분포와 크게 다르다면 KL 발산 항이 충분히 영향을 미치지 못한 것이므로 재구성 손실 가중치를 감소시켜야 한다.
잠재 공간의 처음 50개 차원이 나타나 있다. 표준 정규 분포와 비슷한 모양

3.5.3 새로운 얼굴 생성
n_to_show = 30
znew = np.random.normal(size = (n_to_show,vae.z_dim))
reconst = vae.decoder.predict(np.array(znew))
fig = plt.figure(figsize=(18, 5))
fig.subplots_adjust(hspace=0.4, wspace=0.4)
for i in range(n_to_show):
ax = fig.add_subplot(3, 10, i+1)
ax.imshow(reconst[i, :,:,:])
ax.axis('off')
plt.show()- 표준 정규 분포에서 200개의 차원을 가진 30개의 포인트를 샘플링한다.
- 이 포인트를 디코더에 전달한다.
- 결과 이미지를 출력한다.

샘플링된 포인트를 받아 확실한 사람의 얼굴 이미지로 변환했다.
3.5.4 잠재 공간상의 계산
이미지를 저차원 공간으로 매핑하면 잠재 공간의 벡터에 대해 연산을 수행할 수 있다는 장점이 있다. 연산의 결과를 원본 이미지 차원으로 디코딩하면 시각적으로 비슷한 효과를 만든다.