1. GEMM (General Matrix-Matrix Multiplication)
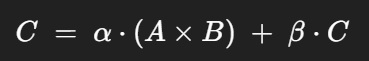
- alpha - 새 계산 값의 크기 조절
- 스칼라 계수, 결과 스케일링에 사용
- beta - 기존 C 값의 보존량
- 스칼라 계수, 기존의 C 행렬에 곱해진 후 더해짐
- beta = 0 - C 의 기존 값은 무시되고 덮어쓰기
- beat = 1 - C 의 기존 값과 새 결과를 합산
2. gemm_rm_tf 의 네이밍 해석 - row-major 포맷 행렬들 사이에서 TF32 정밀도로 수행하는 GEMM
백엔드/프레임워크 내부 규현 규현 규약
- rm -> row-major (행 우선 저장)
- CPU 의 일반적인 배열 포맷
- cm -> column-major
- tf -> tensorFloat-32(TF32)
- 연산 정밀도
Transformer 에서 자주 나오는 차원 표기
기존 심볼
- B = Batch size (묶어서 학습하는 샘플 수)
- T = Sequence length (토큰 길이, time step)
- C = Embdding dimension (모델 차원)
- H = Number of heads (multi-head attention 의 head 수)
- Dh = Head dimension (각 head 의 벡터 차원)
입력 X 가 있다고 할 때:
- X : (B, T, C) -> 문장 배치 (배치 32, 문장 길이 128, 임베딩 512 같은 구조)
- Q, K, V 생성
- 선형층 후 reshape : (B, T, C) -> (B, H, T, Dh)
- 이제 각 head 마다 (T, Dh) 시퀀스를 따로 처리
- Attention 가중치: (B, H, T, T)
- Head merge 후: 다시 (B, T, C)
'dev_AI_framework' 카테고리의 다른 글
| on-the-fly 전치 + 타일렁 누적 VS cuBLAS 의 비교 (0) | 2025.08.31 |
|---|---|
| 현재 GEMM 구현 내용 (0) | 2025.08.31 |
| Attention/Transformer Layer 를 구현하려면 - 기저 연산들의 구현 필요 (1) | 2025.08.31 |
| attention, transformer layer 구현하기 - Attention, transformer 란? (1) | 2025.08.31 |
| CuPy 백엔드 방식과 직접 cuBLAS 래퍼 방식의 사용 (1) | 2025.08.29 |