Lane = ALU(레인) durgkfwk
- warp ( 32 threads ) 안의 thread ID
- 실행 유닛
- 각 lane 은 자신만의 register file 을 가진 작은 연산자
- 코드에서 threadIdx.x % 32 로 정해짐
- 데이터 계산 주체
Bank = Shared Memory 의 하위 모듈(슬롯)
- shared memory 를 32 개 조각으로 나눈 메모리 포트
- 동시 접근성 때문에 존재
- 주소 마지막 5비트에 의해 bank 가 선택됨
- 데이터를 저장/로드 하는 채널
lane = 계산하는 주체 ( 스레드 )
bank = 32 칸으로 나뉜 저장고
lane 이 어떤 bank 를 hit 할지는 lane ID 가 아니라 메모리 주소가 결정하는 것
naive layout 에서는 col = lane 이라서 자연스럽게 동일 개념처럼 착각
Tensor Core Idmatrix 패턴의 등장...!
Tensor Cord 의 Idmatrix 로드 패턴은 warp 의 lane 들이 특정 형태의 행렬 조각을 읽어야 한다.
이때 필연적으로 다음의 구조가 생김
lane0 → A[row + 0][col]
lane0 → A[row + 1][col]
lane0 → A[row + 2][col]
...
lane1 → A[row + 0][col+1]
lane1 → A[row + 1][col+1]
lane1 → A[row + 2][col+1]- lane 0 은 col = 0,
- 1 은 1
- n 은 n
col = laneID 가 성립됨
그런데 행이 바뀔 때 stride 가 32 로 고정
Tensor Core 는 matirx tile load 시
addr = row * 32 + col
이렇게 32 stride 를 강제해버림, 그래서 lane 이 읽는 주소는
lane0 은 bank0 ... 이런 식으로 고정됨
어떤 문제를 발생시키는지
warp 32 개 lane 이 동시에 load 를 할 때,
각 bank 는 한 cycle 에 1개의 요청만 처리
모든 bank conflict 의 발생
swizzle 을 통해 해결
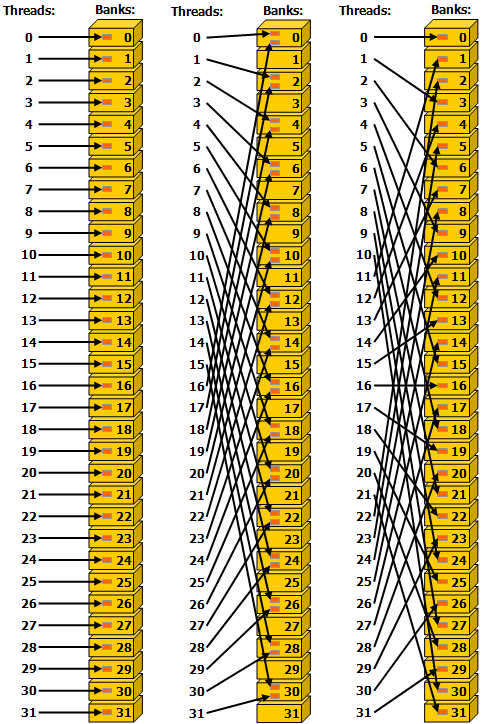
laneID = bankID 라는 정렬을 깨트려서 lane 이 다른 bank 로 접근하도록
warp lane 들은 row-wise 로 아주 좁은 폭만 읽음
- lane 0 - col0, col1
- lane 1 - col2, col3
- ...
- row 는 0~7 에 대해서만 반복적인 접근
Tensor Core 의 tile load 는 “행(row)” 방향으로 8 또는 16개의 row 를 읽는데,
각 row 에 대해 lane 이 읽는 col 은 only 2개(or 4개) 고정이다.
이로 인해 홀짝만 뒤집으면 해결됨
'GPU-KERNEL' 카테고리의 다른 글
| TN 에 이어서 occupancy 측정 (0) | 2025.11.30 |
|---|---|
| Register Tiling TN Sweep test TN 이 증가하면, ILP (Instruction Level Parallelism) 증가 (0) | 2025.11.30 |
| Shared Memory Bank Conflict Test - padding 을 통해 bank conflict 회피 가능 (0) | 2025.11.30 |
| Fragment layouy visualize test (0) | 2025.11.30 |
| SMEM Tile Size Sweep test (0) | 2025.11.30 |