분류 문제를 두 개의 단계로 나누어 보았다.
첫 번째는 추론 단계로 훈련 집단을 활용하여 p(C_k|x) 에 대한 모델을 학습시키는 단계다.
두 번째는 결정 단계로 학습된 사후 확률들을 이용하여 최적의 클래스 할당을 시행하는 것이다.
두 가지 문제를 한 번에 풀어내는 방식도 생각해 볼 수 있다. x 가 주어졌을 때 결정값을 돌려준느 함수를 직접 학습시키는 것이다. 이러한 함수를 판별 함수 discriminant function 라고 한다.
사실 결정 문제를 푸는 데 세 가지 다른 접근법이 있다. 이 세 가지 접근법은 모두 실제로 활용되고 있다.
a
우선 각각의 클래스 C_k 에 대해서 조건부 확률 밀도 p(x|C_k) 를 알아내는 추론 문제를 풀어낸다. 클래스별 사전 확률 p(C_k) 도 따로 구한다. 그 후에 다음의 식과 같이 베이지안 정리를 적용해서 각 클래스별 사후 확률 p(C_k|x) 를 구한다.

베이지안 정리의 분모는 분자에 나타난 항들을 이용하여 구할 수 있다.
이와 동일하게 결합 분포 p(x,C_k) 를 직접적으로 모델링한 후 정규화해서 사후 확률을 구할 수도 있다. 사후 확률을 구한 후에는 결정 이론을 구한 후에는 결정 이론을 적용하여 각각의 새 입력 변수 x 에 대한 클래스를 구한다. 직간접적으로 입력값과 출력값의 분포를 모델링하는 이러한 방식을 생성 모델 generative model 이라고 한다. 왜냐하면 이렇게 만들어진 분포로부터 표본을 추출함으로써 입력 공간에 합성 데이터 포인트들을 생성해 넣는 것이 가능하기 대문이다.
b
우선 사후 확률 p(C_k|x) 를 계산하는 추론 문제를 풀어낸 후에 결정 이론을 적용하여 각각의 입력 변수 x 에 대한 클래스를 구한다. 사후 확률을 직접 모델링하는 이러한 방식을 판별 모델이라고 한다.
c
각각의 입력값 x 를 클래스에 사상하는 판별 함수 f(x) 를 찾는다. 예를 들어, 두 개의 클래스를 가진 문제의 경우에 f() 는 이진값을 출력으로 가지는 함수로써, f = 0 일 경우 클래스 C_1, f = 1 일 경우 C_2 로 표현할 수 있다.
a 는 가장 손이 많이 가는 방식이다. 왜냐하면 x 와 C_k 에 대해서 결합 분포를 찾아야 하기 때문이다. 많은 응용 사례에서 x 는 고차원이며, 따라서 각각의 클래스에 대해 일정 수준 이상의 조건부 밀도를 구하기 위해서는 상당히 많은 훈련 집합이 필요할 수 있다. 많은 경우에 클래스별 사전 확률 p(C_k)는 훈련 집합의 클래스 별 비율을 계산하는 것으로 간단히 계산할 수 있다. a 의 장점은 이 방식을 사용하면 데이터 p(x) 의 주변 밀도도 구할 수 있다는 것이다. 이를 바탕으로 주어진 모델 하에서 발생 확률이 낮은 새 데이터 포인트를 미리 발견해 낼 수 있다. 이러한 데이터 포인트들에 대해서는 예측 모델이 낮은 정확도를 보이게 되리 것이다.
이런 검출 방식을 이상점 검출 outlier detection, 새것 검출 novelty detection 이라고 한다.
하지만 분류 알고리즘을 통해서 결정을 내리는 것만이 목표일 경우 결합 분포를 계산하는 것은 낭비다. 또한, 데이터 요구량도 너무 크다.
이런 경우 사후 확률 p(C_k|x) 를 직접 계산하는 b 방식이 훨씬 더 효율적일 것이다. 클래스별 조건부 분포에는 사후 확률에 영향을 미치지 않는 추가적인 정보가 많이 포함되어 있을 수 있다.
머신러닝에서 생성 모델과 판별 모델 각각을 사용하는 것의 장단점의 논의가 많이 있으며 두 모델링 방식을 합치는 것에 대해서도 여러 시도가 있었다.
c 는 더 간단하다 훈련 집합을 사용하여 각각의 변수 x 를 해당 클래스에 사상하는 판별 함수 f(x) 를 직접 찾아내는 방식이다. 추론 단계와 결정 단계를 하나의 학습 문제로 합친 것이다. 아래 글미의 예시에서 녹색 수직 선에 해당하는 x 값을 찾아내는 것이 c 방식에 해당한다. 녹색 선이 오분류 확률을 최소화하는 결정 경계이기 때문이다.
하지만 c 방식을 사용할 경우 사후 확률 p(C_k|x) 들을 알지 못하게 된다는 단점이 있다. 사후 확률을 구하는 것이 유의미한 것은 다음과 같은 여러 가지 이유 때문이다.
위험의 최소화
손실 행렬의 값들이 때때로 변하는 문제를 고려, 만약 사후 확률을 알고 있다면, 쉽게 최소 위험 결정 기준을 구할 수가 있다. 반면에 판별 함수만 알고 있을 경우에는 손실 행렬의 값이 변할 때마다 훈련 집합을 활용하여 분류 문제를 새로 풀어야 할 것이다.
거부 옵션
사후 확률을 알고 있다면 주어진 거부 데이터 포인트 비율에 대해 오분류 비율을 최소화하는 거부 기준을 쉽게 구할 수 있다.
클래스 사전 확률에 대한 보상
각 클래스 별 데이터 개수의 차이에 따른 학습이 어려울 수 있다. 때문에 각각의 클래스에 같은 숫자의 예시를 선택한 균형 잡힌 데이터 집합을 활용하면 더 정확한 모델을 찾아낼 수 있을 수 있다.
하지만 그렇게 할 경우 훈련 집합을 변경한 것에 대한 보상을 적용해야 한다. 이러한 수정된 데이터 집합을 사용하여 사후 확률에 대한 모델을 찾아냈다고 가정. 사후 확률은 베이지안 정리로부터 사전 확률에 비례함을 알 수 있다.
따라서 인공의 균형 잡힌 데이터 집합에서 구한 사후 확률을 인공 데이터 집합의 클래스 비율로 나누고, 여기에 우리가 실제로 모델을 적용할 모수 집합의 클래스의 비율을 곱함으로써 수정된 사후 확률을 구할 수가 있다. 최종적으로는 새 사후 확률의 합이 1이 되도록 정규화해야 한다.
사후 확률을 구하는 방식을 사용하는 대신 직접 판별 함수를 구하는 방식으로 학습을 시킨 경우에는 이러한 수정이 불가능하다.
모델들의 결합
복잡한 응용 사례의 경우 하나의 큰 문제를 여러 개의 작은 문제로 나누어서 각각의 분리된 모듈로써 해결하는 것이 바람직한 경우가 있다.
두 모델이 각 클래스에 대한 사후 확률을 제공하기만 한다면 확률의 법칙을 적용하여 시스템적으로 서로 다른 출력값을 합하는 것이 가능하다.
이를 위한 한 가지 쉬운 방법은 각 클래스에 대해서 각 데이터의 분포가 독립적이라고 가정하는 것이다.
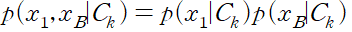
이는 조건부 독립 conditional independency 성질의 예시다. 분포들이 클래스에 포함된다는 조건하에 독립적이기 때문이다. 이를 바탕으로 엑스레이 이미지와 혈액 데이터가 주어졌을 때의 사후 확률을 다음과 같이 구할 수 있다.
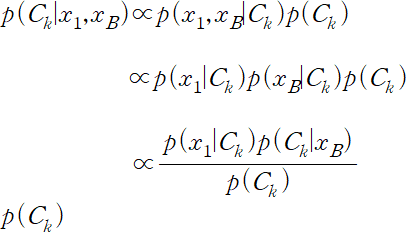
클래스 사전 확률이 필요한데, 이는 데이터 포인트들의 각 클래스별 비율로부터 쉽게 유추하는 것이 가능하다.
그리고 최종적으로 사후 확률을 정규화하여 합이 1이 되도록 하는 과정이 필요하다.
특정 조건부 독립 과정은 나이브 베이즈 모델의 예시다. 결합 확률 분포는 보통 나이브 베이즈 모델하에서는 인수분해가 되지 않는다.
'개념 정리' 카테고리의 다른 글
| 정보 이론 (1) | 2022.12.20 |
|---|---|
| 결정 이론(회귀에서의 손실 함수) (1) | 2022.12.20 |
| 결정 이론(거부 옵션) (0) | 2022.12.19 |
| 결정 이론(기대 손실의 최소화) (0) | 2022.12.19 |
| 결정 이론(오분류 비율의 최소화) (0) | 2022.12.19 |


